4.1. Full-Unrolling of Innermost Loop with Non-Contiguous Data Access¶
4.1.1. Motivation¶
Fujitsu Fortran/C/C++ compilers vectorize innermost loops. Therefore, if an index of the first dimension (for Fortran programs) for an array reference within an innermost loop is not the do-variable for the innermost loop, the array accesses are not contiguous and lead to more busy time for cache access.
However, when the iteration count for the innermost loop is constant and small, full-unrolling of the innermost loop might make the index of the first dimension for the array reference to be the do-variable for the vectorized loop.
As a result, array accesses become contiguous, the busy time for cache access decreases and it might lead to reduction of execution time.
4.1.2. Applied Example¶
Referring to an example presented in “Meetings for application code tuning on A64FX computer systems”, performance improvement by applying this technique is shown below. In this example, an OCL of “fullunroll_pre_simd” was added to a loop for do-variable IP, which has non-contiguous references to an array F.
!$OMP PARALLEL DO PRIVATE(FBUF)
DO IG = 1, NG3
V1(IG) = 0.D0
V2(IG) = 0.D0
V3(IG) = 0.D0
V4(IG) = 0.D0
DO IP = 1, 15
FBUF = F(IG,IP)
V1(IG) = V1(IG) + FBUF
V2(IG) = V2(IG) + FBUF*CVEL(1,IP)
V3(IG) = V3(IG) + FBUF*CVEL(2,IP)
V4(IG) = V4(IG) + FBUF*CVEL(3,IP)
END DO
END DO
!$OMP PARALLEL DO PRIVATE(FBUF)
DO IG = 1, NG3
V1(IG) = 0.D0
V2(IG) = 0.D0
V3(IG) = 0.D0
V4(IG) = 0.D0
!OCL FULLUNROLL_PRE_SIMD
DO IP = 1, 15
FBUF = F(IG,IP)
V1(IG) = V1(IG) + FBUF
V2(IG) = V2(IG) + FBUF*CVEL(1,IP)
V3(IG) = V3(IG) + FBUF*CVEL(2,IP)
V4(IG) = V4(IG) + FBUF*CVEL(3,IP)
END DO
END DO
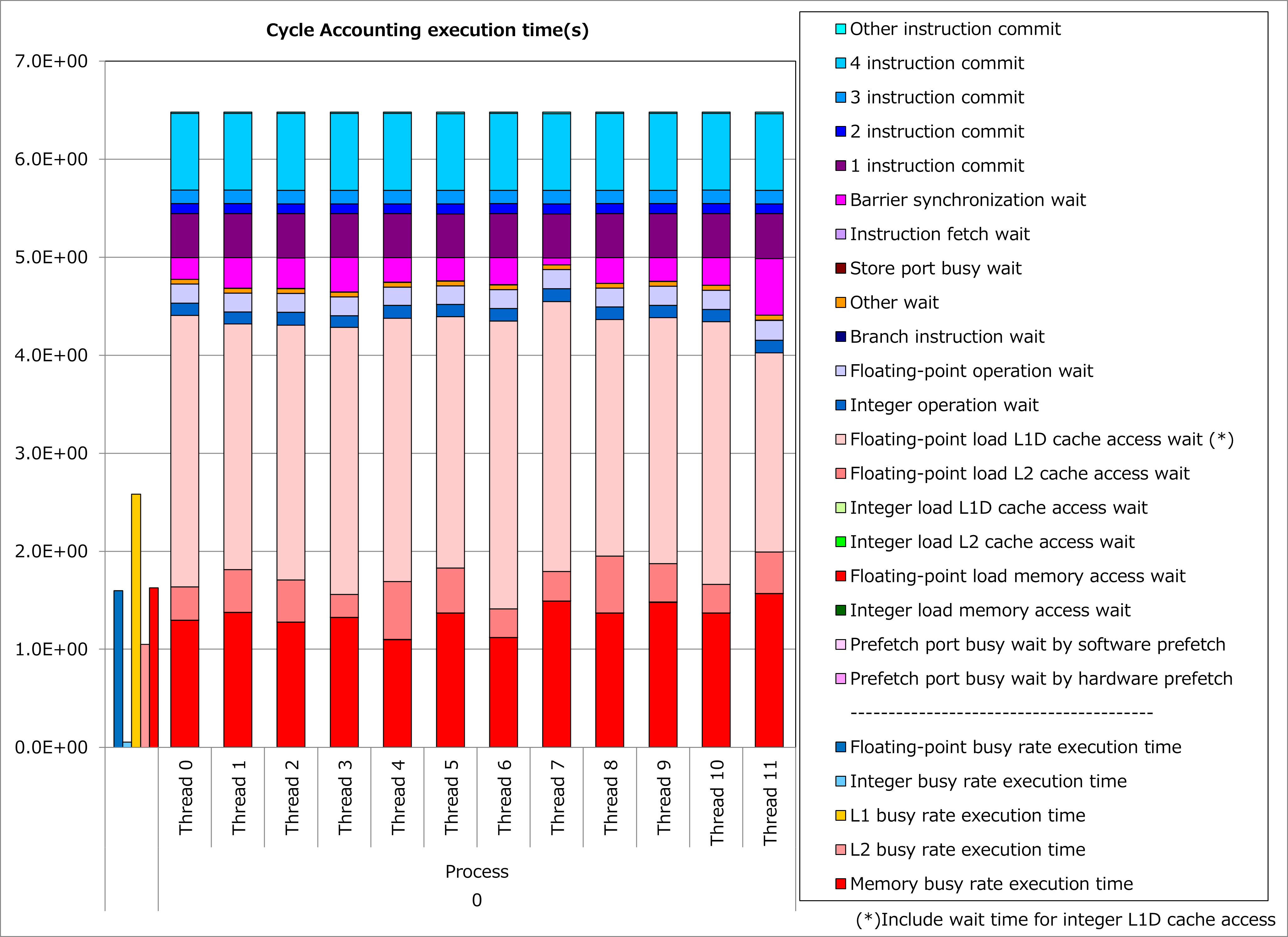
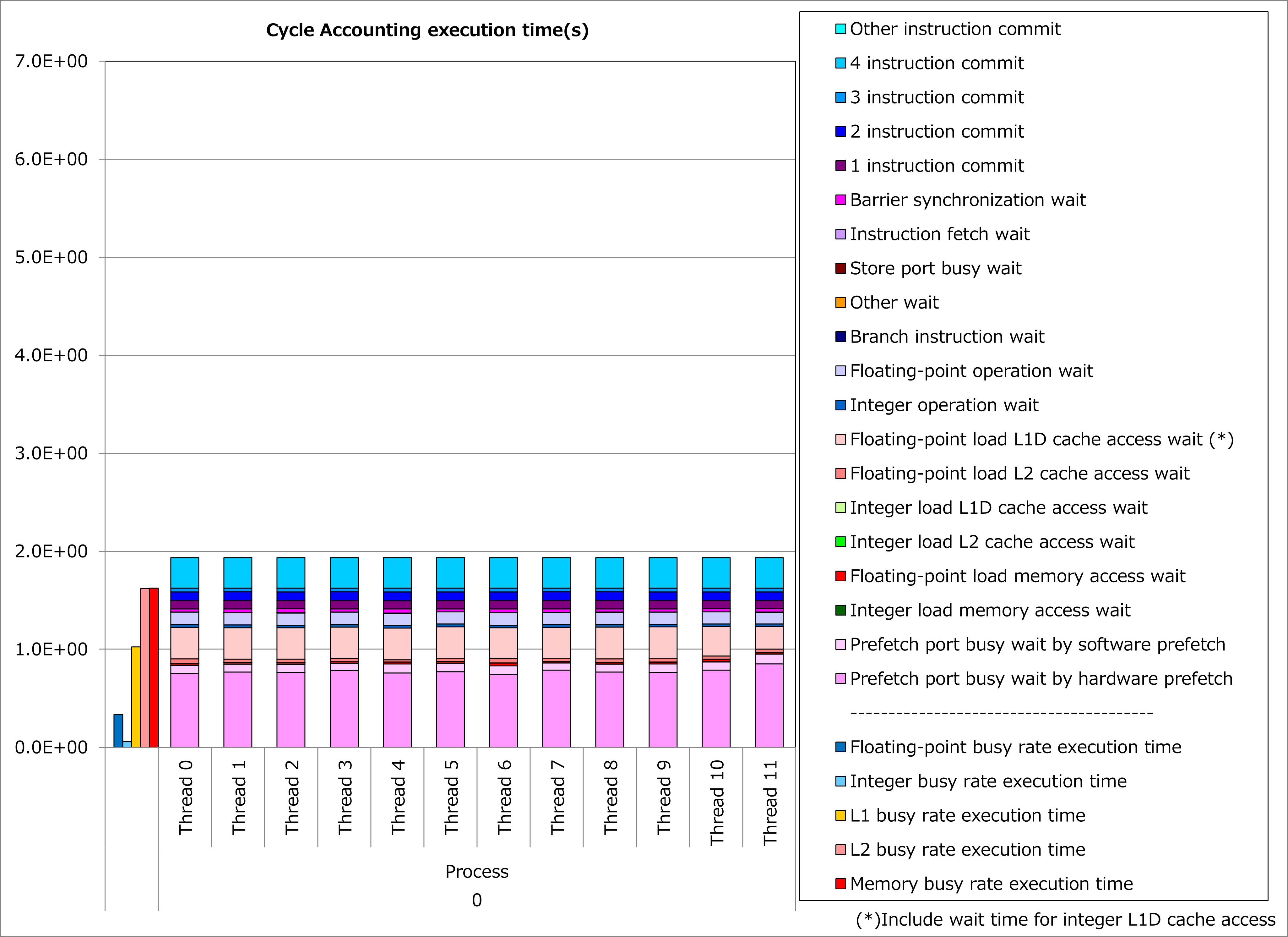
Results of cycle accounting for executions before/after applying the technique are shown in graphs below. A parameter for the loop execution is as follows:
NG3 = 131 3
Comparing the right graph for the technique applied to the left graph for the original, busy time for L1D cache access was reduced by half, waiting time for L1D cache access dropped dramatically and execution time was reduced by 70%.
4.1.3. Real Cases¶
Real cases related to this technique are presented in “Meetings for application code tuning on A64FX computer systems” as follows:
4.1.4. References¶
Notice: Access rights for Fugaku User Portal are required to read the above documents.