4.1. 除算処理のSIMD化と小回転ループのSIMD化抑止¶
4.1.1. チューニング対象¶
本節で対象とした calc_function_3 関数は、「システム方程式マトリクス計算」の計測区間に含まれ、チューニング実施前のアプリケーション全体の約1.6%のコストを占めている関数です。
4.1.2. 分析¶
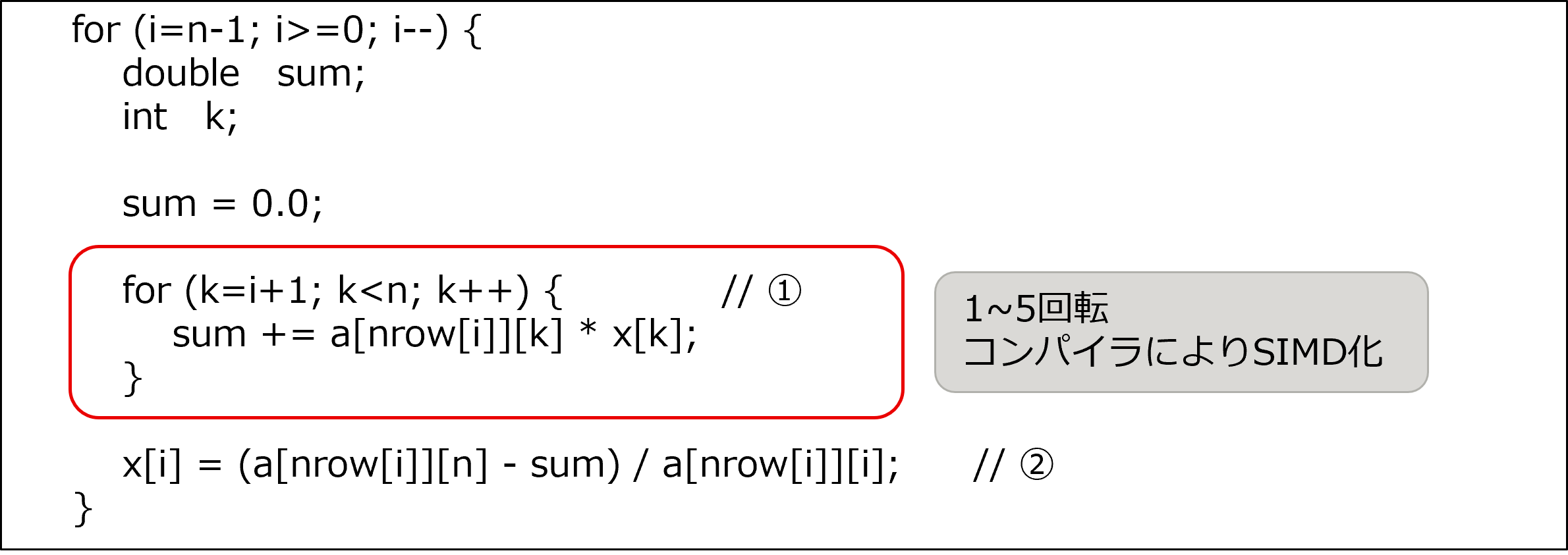
calc_function_3 関数を分析した結果、下記のループに着目しました。このループの特徴は以下の通りです。
コンパイラにより、ソースコード抜粋の①のループが SIMD 化されますが、ループ回転数が少ないです。
①のループには、SIMD 化によって水平加算( SIMD 内の全要素の和を取る命令)のコストが発生していると考えられます。
ループ内の除算処理(ソースコード抜粋の②)が SIMD 化されていません。
[チューニング実施前の calc_function_3 関数のソースコード抜粋]
4.1.3. 実施¶
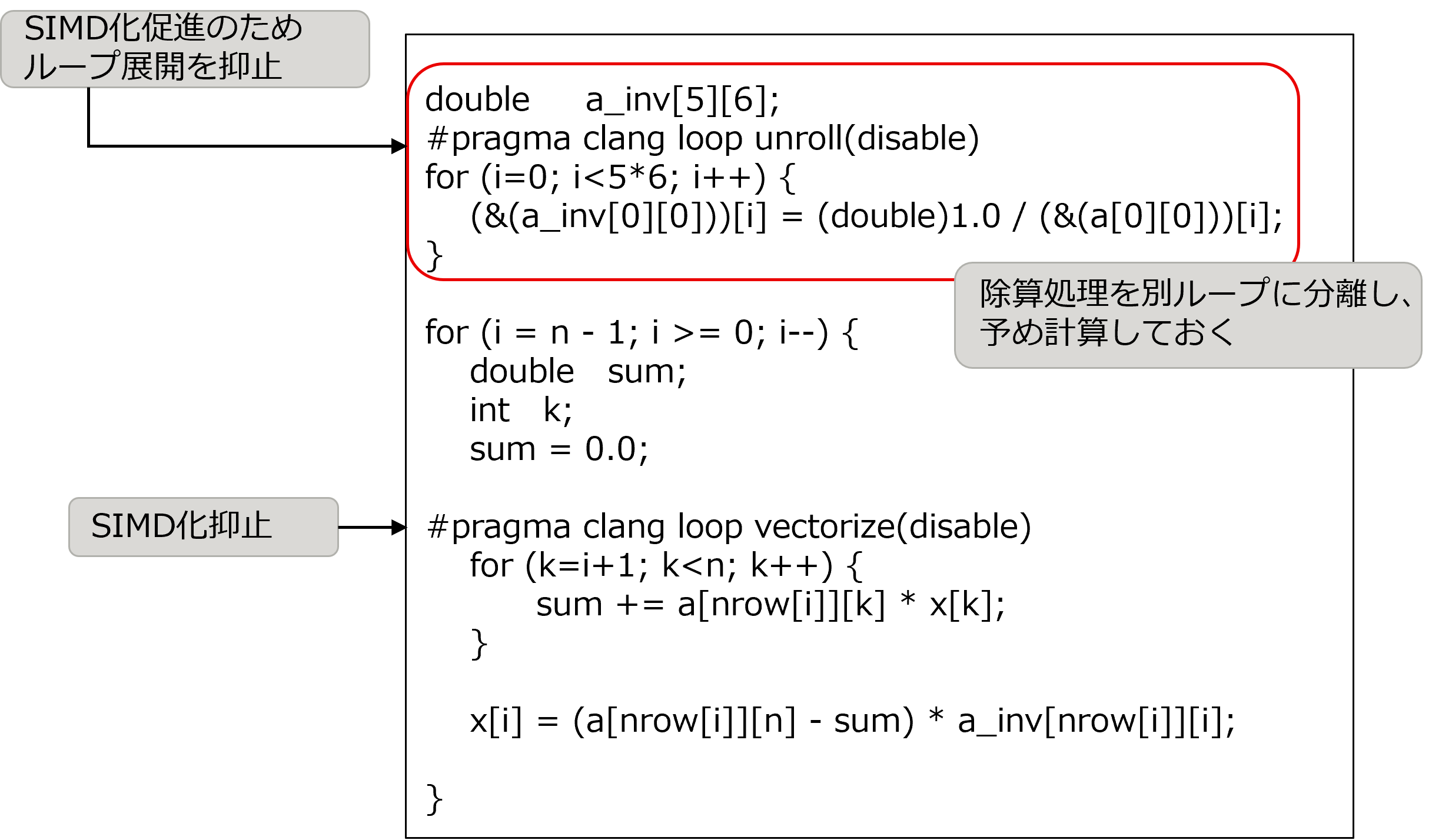
分析結果を踏まえて、以下のチューニングを実施しました。
配列 a_inv を用意し、除算処理を別ループに分離し、事前に実施します(分析の結果、a_inv に必要な配列サイズは 5×6 と判明)。なお除算処理のループは、ループ展開を抑止することで SIMD 化が促進されるようにします。
最内ループは最適化制御行にて SIMD 化を抑止します。
以下は、チューニング実施後のソースコードです。
[チューニング実施後の calc_function_3 関数のソースコード抜粋]
4.1.4. 効果の検証¶
実施したチューニングの効果を、チューニング実施前後の基本プロファイラを用いて評価しました。下表はコストの計測結果です。本節のチューニングにより calc_function_3 関数のコストが30%減少し、アプリケーション全体のコストが1.4%減少しました。
コスト |
性能改善率 ((A-B)/A) |
||
|---|---|---|---|
本節のチューニング実施前 (A) |
本節のチューニング実施後 (B) |
||
アプリケーション全体 |
5975125 |
5889171 |
1.4% |
calc_function_3 |
164184 |
114805 |
30.1% |