4.9. 最適化制御行を使わないループ展開¶
4.9.1. チューニング対象¶
本節で対象とした calc_function_4 関数は、「システム方程式マトリクス計算」の計測区間に含まれ、チューニング実施前のアプリケーション全体の約1.0%のコストを占めている関数です。本関数は「システム方程式マトリクス計算」に含まれる関数の中では、4番目にコストが高い関数です。
4.9.2. 分析¶
calc_function_4 関数を分析した結果、下記のループに着目しました。このループの特徴は以下の通りです。
ソースコード抜粋の①ループの外にある if 文(既に実施したチューニング項目で追加)により、①ループの回転数は5であることが明示され、ループ展開されました。対して、②のループは①ループと異なり展開されませんでした。
[チューニング実施前の calc_function_4 関数のソースコード抜粋]

4.9.3. 実施¶
分析結果を踏まえて、以下のチューニングを実施しました。
命令スケジューリング最適化のため、ソースコード抜粋の②のループを最適化制御行でループ展開します。
[チューニング実施後の calc_function_4 関数のソースコード抜粋]

しかしながら、上記最適化制御行ではコンパイラによるループ展開ができなかったため、代わりに次のチューニングを実施しました。
ソースコード抜粋の②のループを、最適化制御行を使わずにループ展開
[チューニング実施後の calc_function_4 関数のソースコード抜粋]

4.9.4. 効果の検証¶
実施したチューニングを評価するために、詳細プロファイラで出力した、「システム方程式マトリクス計算」計測区間の Cycle Accounting(プログラムの実行時間の内訳)を、チューニング実施前後で比較しました。
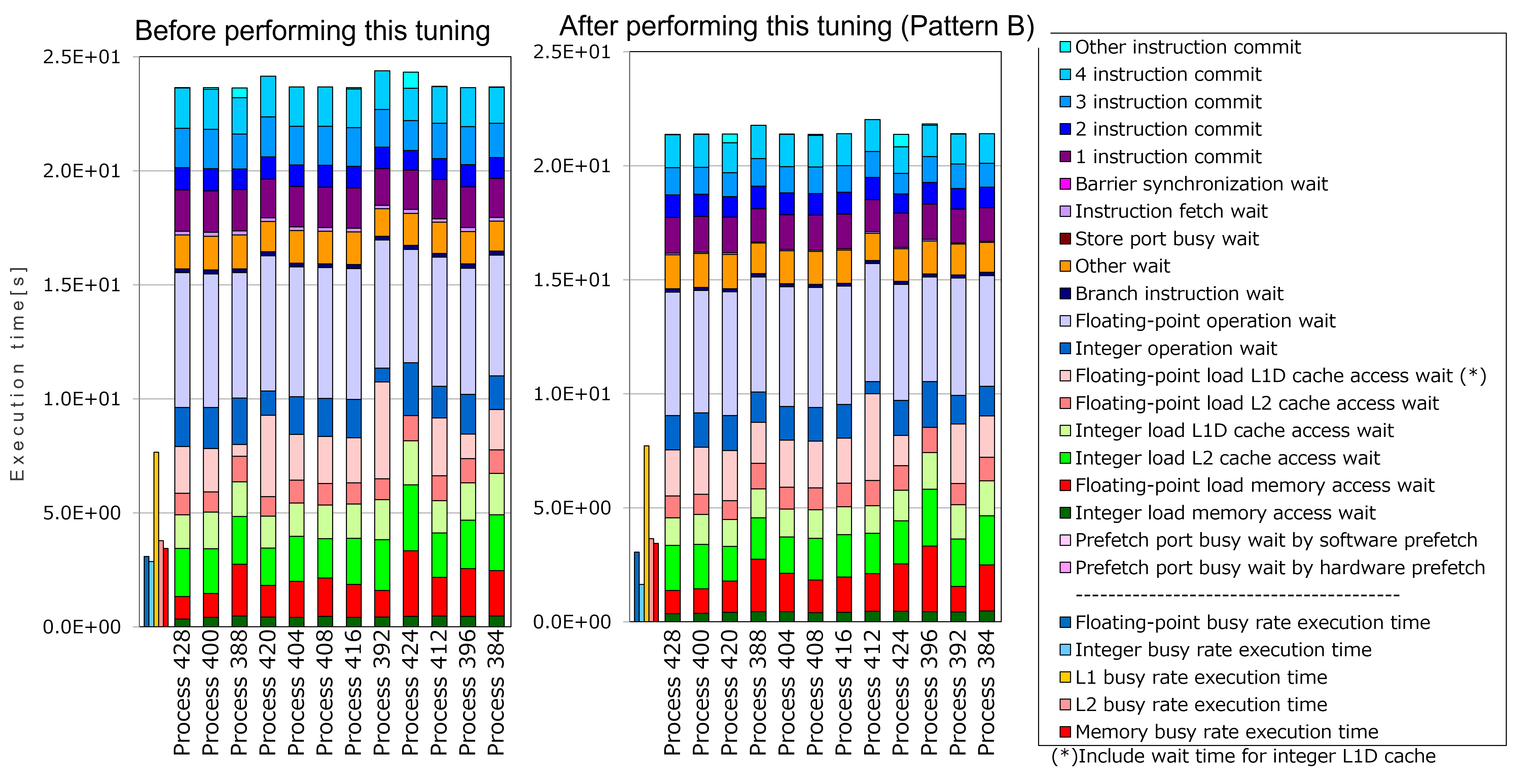
上記グラフのうち、チューニング実施前の中で最も実行時間が長いプロセス(Process 392)と、チューニング実施後の中で最も実行時間が長いプロセス(Process 412)を比較すると、チューニング実施後では約10%実行時間が改善しました。プロセスごとの出力項目をみると「Floating-point operation wait」が共通して改善しており、ループ展開によるスケジューリング改善の効果が表れていると考えられます。