4.4. ループ回転方向変更¶
4.4.1. チューニング対象¶
本節で対象とした othSolv_function_3 関数は、「システム方程式以外の方程式処理」の計測区間に含まれ、チューニング実施前のアプリケーション全体の約0.8%のコストを占めている関数です。
4.4.2. 分析¶
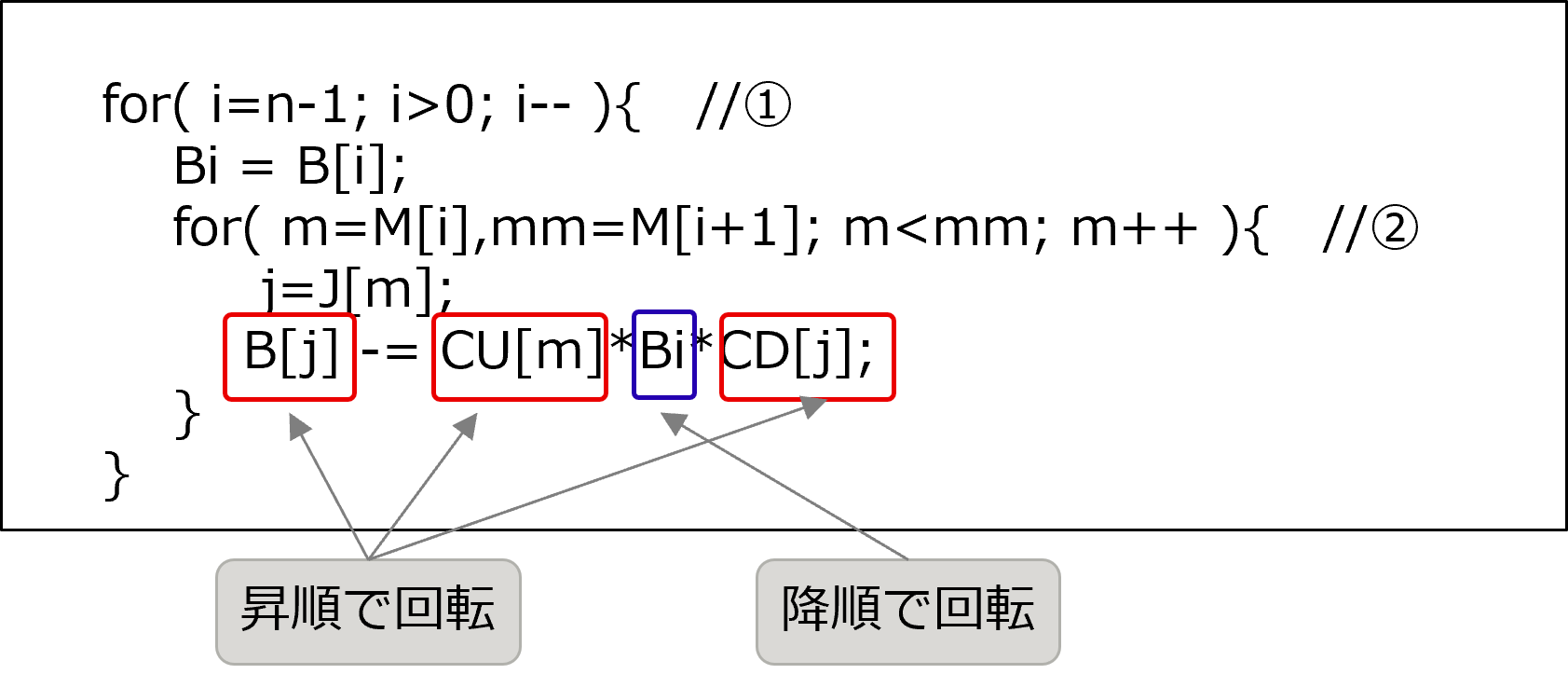
othSolv_function_3 関数を分析した結果、下記のループに着目しました。このループの特徴は以下の通りです。
ソースコード抜粋の①のループは降順で回転しますが、②のループは昇順で回転します。
二重ループのそれぞれの回転方向が異なるため、ハードウェアプリフェッチが当たりづらくなることが予想されます。
[チューニング実施前の othSolv_function_3 関数のソースコード抜粋]
4.4.3. 実施¶
分析結果を踏まえて、以下のチューニングを実施しました。
ソースコード抜粋の②のループの回転方向を①と同じく降順に変更します。
[チューニング実施後の othSolv_function_3 関数のソースコード抜粋]
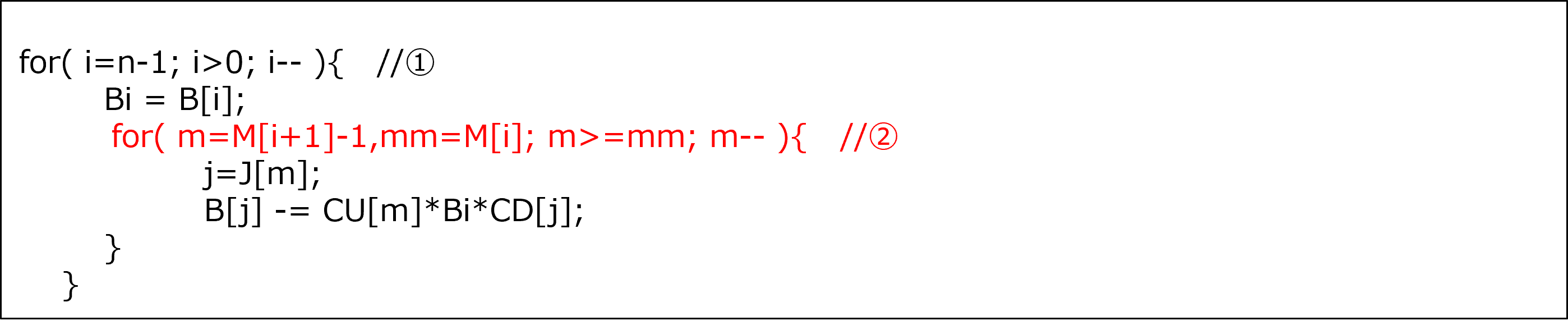
4.4.4. 効果の検証¶
実施したチューニングを評価するために、詳細プロファイラで出力した、チューニングを実施したループ(上記ソースコード抜粋の①)の Cycle Accounting(プログラムの実行時間の内訳)を、チューニング実施前後で比較しました。
以下の各グラフは、ある1つのコアメモリグループに割り当てられた12個のプロセスの Cycle Accounting を、割り当てられた順に示しています。各プロセスは、1ノードに4つあるコアメモリグループに順番に1つずつ割り当てられるため、4つおきのプロセス番号になります。
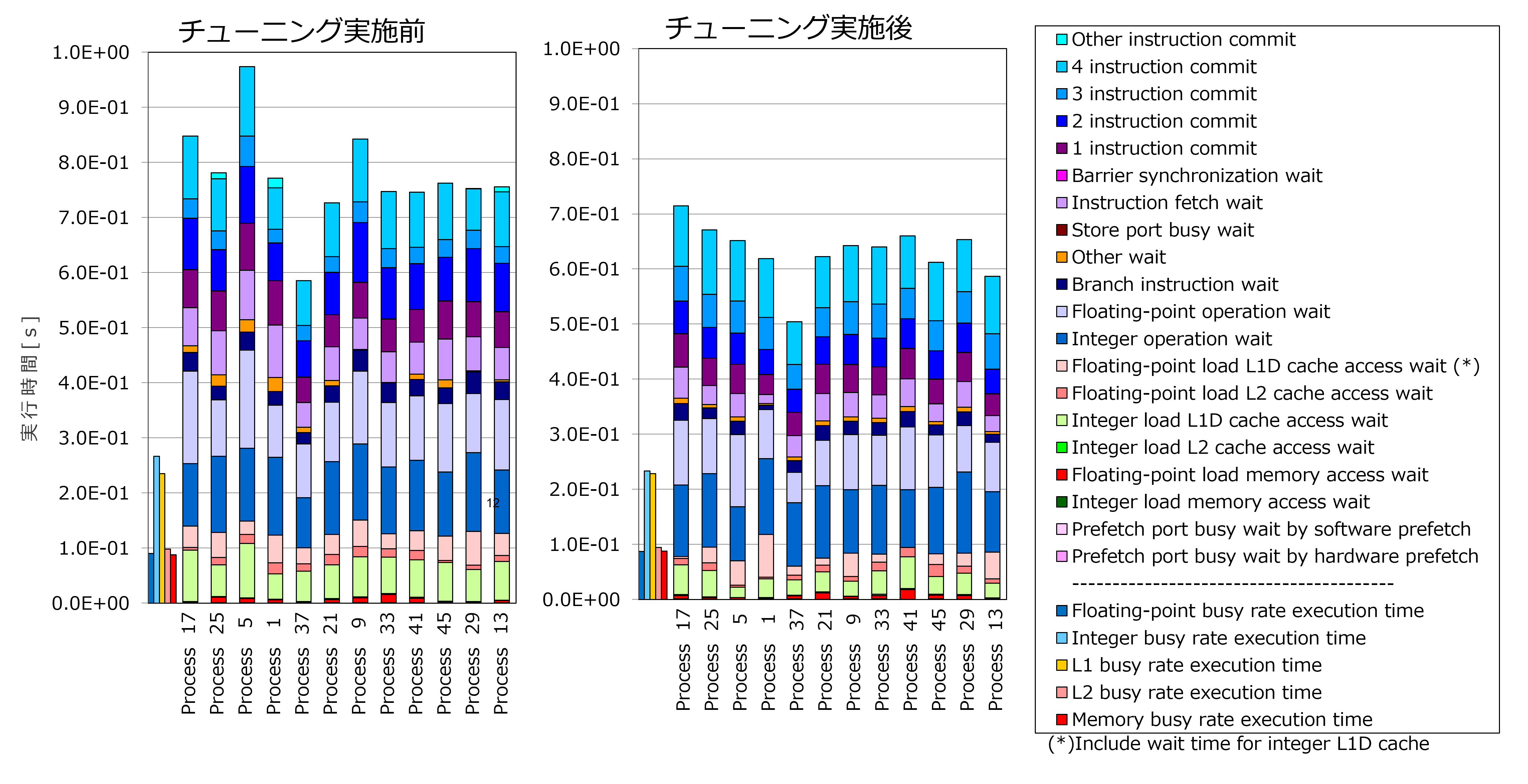
上記グラフのうち、チューニング実施前の中で最も実行時間が長いプロセス(Process 5)と、チューニング実施後の中で最も実行時間が長いプロセス(Process 17)を比較すると、チューニング実施後では約27%実行時間が改善しました。実行時間の内訳をみると「Integer load L1D cache access wait」と「Instruction fetch wait」が特に改善しており、これは本節のチューニングによりプリフェッチが当たりやすくなった効果と考えられます。
また「Floating-point operation wait」も改善が見られました。これは本節のチューニングにより命令スケジューリングが改善されたためと考えられます。