4.5. SVE ACLEによるSIMD化¶
4.5.1. チューニング対象¶
本節で対象とした calc_function_4 関数は、「システム方程式マトリクス計算」の計測区間に含まれ、チューニング実施前のアプリケーション全体の約1.0%のコストを占めている関数です。
4.5.2. 分析¶
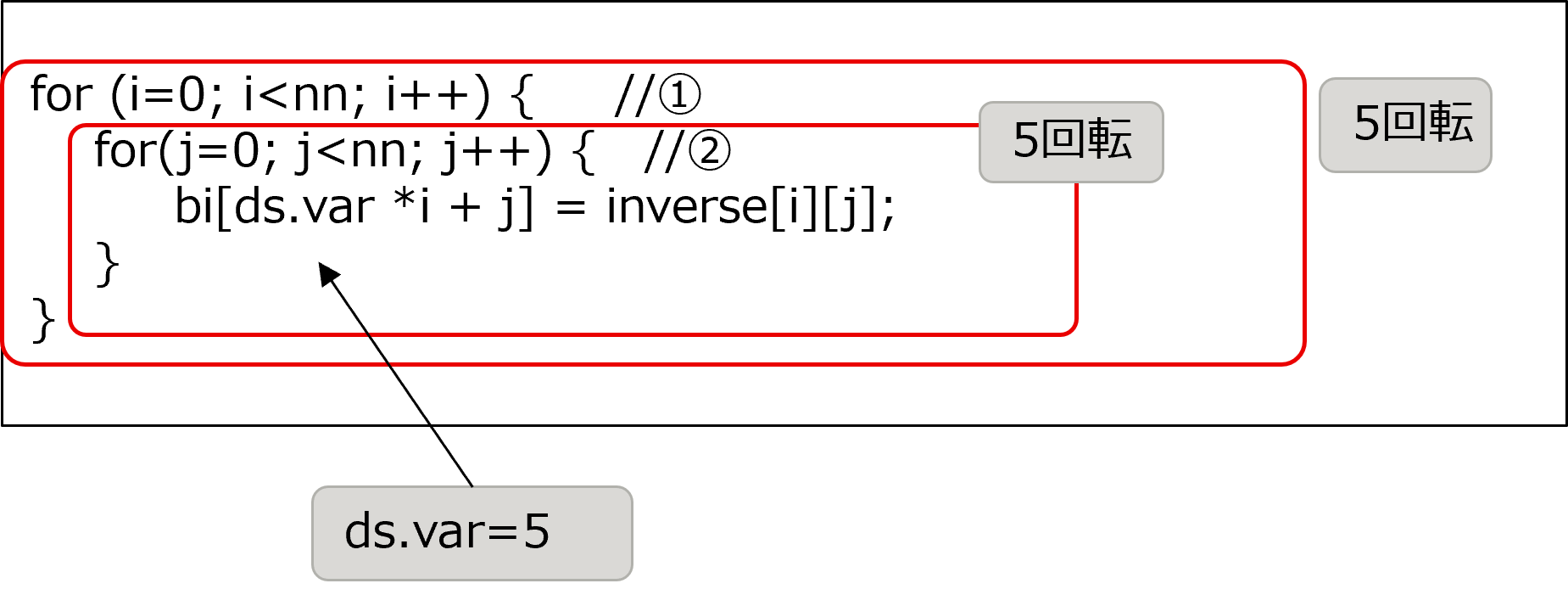
calc_function_4 関数を分析した結果、下記のループに着目しました。このループの特徴は以下の通りです。
ソースコード抜粋の①ループが、コンパイラによる SIMD 化がされていません。
ソースコード抜粋の①②ループはそれぞれ5回転のループです。
4.3節( ループ一重化によるSIMD化促進 )の対象箇所と同じ構造のため、同様にループ一重化による SIMD 化促進の改善が可能です。
[チューニング実施前の calc_function_4 関数のソースコード抜粋]
4.5.3. 実施¶
分析結果を踏まえて、以下のチューニングを実施しました。
4.3節( ループ一重化によるSIMD化促進 )と同様に、ループを一重化し SIMD 化を促進します。
[チューニング実施後の calc_function_4 関数のソースコード抜粋]

上記変更後にコンパイルしたところ、最適化メッセージでは SIMD 化されていましたが、実行すると SVE 命令率は0.0%であり、実際には SIMD 化されていませんでした。そこで次の方法として以下のチューニングを実施しました。
組み込み関数の1つである SVE ACLE(Arm C Language Extensions for SVE:SVE 命令を直接プログラム中に記述する方法)を用いて SIMD 化を行う
[チューニング実施後の calc_function_4 関数のソースコード抜粋]

4.5.4. 効果の検証¶
実施したチューニングを評価するために、詳細プロファイラで出力した、チューニングを実施したループ(上記ソースコード抜粋の①)の Cycle Accounting(プログラムの実行時間の内訳)を、チューニング実施前後で比較しました。
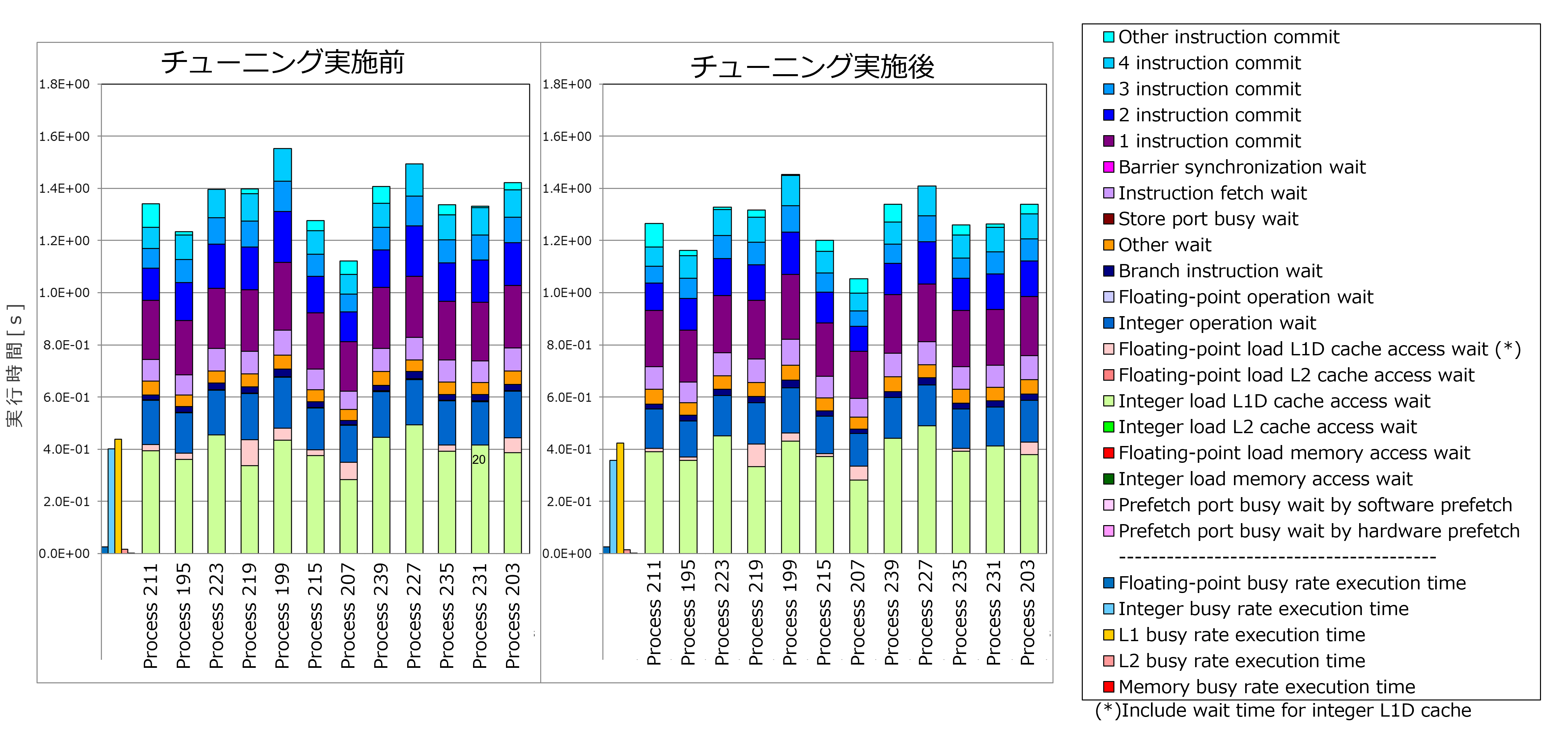
上記グラフのうち、チューニング実施前後の計測結果の中で最も実行時間が長い Process 199 に着目すると、実行時間は1.55秒から1.45秒に短縮し、約6%性能が改善しました。実行時間の内訳をみると「2 instruction commit」が特に改善しており、これは本節のチューニングによる SIMD 化で命令数が削減された効果と考えられます。