2.3. Fission of Imperfectly Nested Loops¶
2.3.1. Motivation¶
Fujitsu Fortran/C/C++ compilers vectorize innermost loops. Therefore, if nested loops are not perfectly nested, i.e. there is an executed statement outside the innermost loop, calculations outside the innermost loop are not vectorized and executed sequentially.
DO j = 1, n
DO i = 1, n
y(j) = y(j) + a(i,j) * x(i)
END DO
END DO
DO j = 1, n
DO i = 1, n
y(j) = y(j) + a(i,j) * x(i)
END DO
y(j) = y(j) / a(j,j)
END DO
When ratio of calculations outside the innermost loop is not ignorable, fission of imperfectly nested loops, which makes multiple perfectly nested loops, might improve ratio of vectorized calculations.
DO j = 1, n
DO i = 1, n
y(j) = y(j) + a(i,j) * x(i)
END DO
END DO
DO j = 1, n
y(j) = y(j) / a(j,j)
END DO
As a result, more calculations are executed simultaneously and it might lead to reduction of execution time.
2.3.2. Applied Example¶
Referring to an example presented in “Meetings for application code tuning on A64FX computer systems”, performance improvement by applying this technique is shown below. In this example, a loop for for-variable i, which is the outer loop for imperfectly nested loops, is distributed into a loop containing one for for-variable m and another for the remainder part.
for(int k = 0; k < p_Nq; ++k) {
for(int j = 0; j < p_Nq; ++j) {
for(int i = 0; i < p_Nq; ++i) {
const int gbase
= element * p_Nggeo * p_Np + k * p_Nq * p_Nq + j * p_Nq + i;
const double r_G00 = ggeo[gbase + p_G00ID * p_Np];
const double r_G01 = ggeo[gbase + p_G01ID * p_Np];
const double r_G11 = ggeo[gbase + p_G11ID * p_Np];
const double r_G12 = ggeo[gbase + p_G12ID * p_Np];
const double r_G02 = ggeo[gbase + p_G02ID * p_Np];
const double r_G22 = ggeo[gbase + p_G22ID * p_Np];
double qr = 0.f;
double qs = 0.f;
double qt = 0.f;
for(int m = 0; m < p_Nq; m++) {
qr += s_D[i][m] * s_q[k][j][m];
qs += s_D[j][m] * s_q[k][m][i];
qt += s_D[k][m] * s_q[m][j][i];
}
s_Gqr[k][j][i] = r_G00 * qr + r_G01 * qs + r_G02 * qt;
s_Gqs[k][j][i] = r_G01 * qr + r_G11 * qs + r_G12 * qt;
s_Gqt[k][j][i] = r_G02 * qr + r_G12 * qs + r_G22 * qt;
}
}
}
double qr[p_Nq];
double qs[p_Nq];
double qt[p_Nq];
for(int k = 0; k < p_Nq; ++k) {
for(int j = 0; j < p_Nq; ++j) {
for(int i = 0; i < p_Nq; ++i) {
qr[i] = 0.f;
qs[i] = 0.f;
qt[i] = 0.f;
for(int m = 0; m < p_Nq; m++) {
qr[i] += s_D[i][m] * s_q[k][j][m];
qs[i] += s_D[j][m] * s_q[k][m][i];
qt[i] += s_D[k][m] * s_q[m][j][i];
}
}
#pragma loop norecurrence
for(int i = 0; i < p_Nq; ++i) {
const int gbase
= element * p_Nggeo * p_Np + k * p_Nq * p_Nq + j * p_Nq + i;
const double r_G00 = ggeo[gbase + p_G00ID * p_Np];
const double r_G01 = ggeo[gbase + p_G01ID * p_Np];
const double r_G11 = ggeo[gbase + p_G11ID * p_Np];
const double r_G12 = ggeo[gbase + p_G12ID * p_Np];
const double r_G02 = ggeo[gbase + p_G02ID * p_Np];
const double r_G22 = ggeo[gbase + p_G22ID * p_Np];
s_Gqr[k][j][i] = r_G00 * qr[i] + r_G01 * qs[i] + r_G02 * qt[i];
s_Gqs[k][j][i] = r_G01 * qr[i] + r_G11 * qs[i] + r_G12 * qt[i];
s_Gqt[k][j][i] = r_G02 * qr[i] + r_G12 * qs[i] + r_G22 * qt[i];
}
}
}
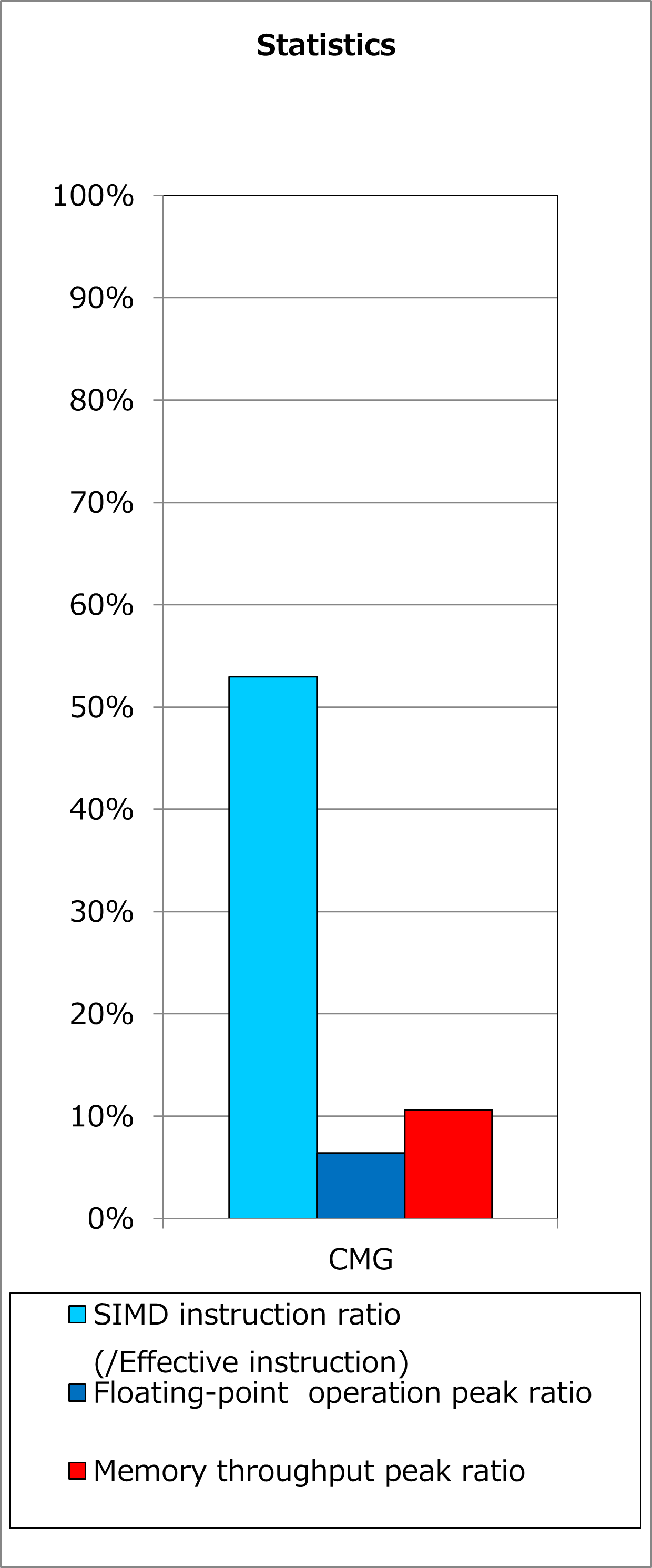
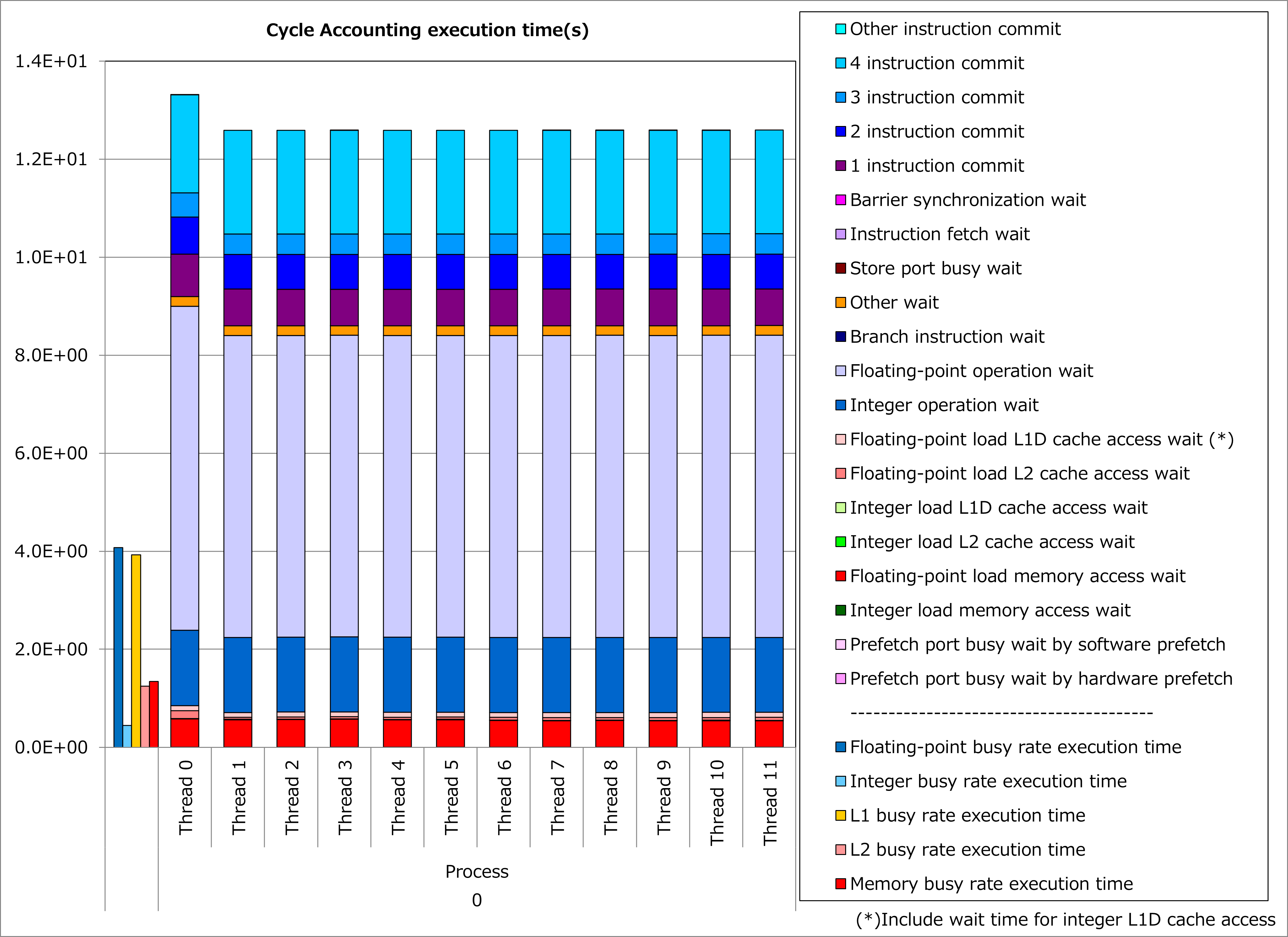
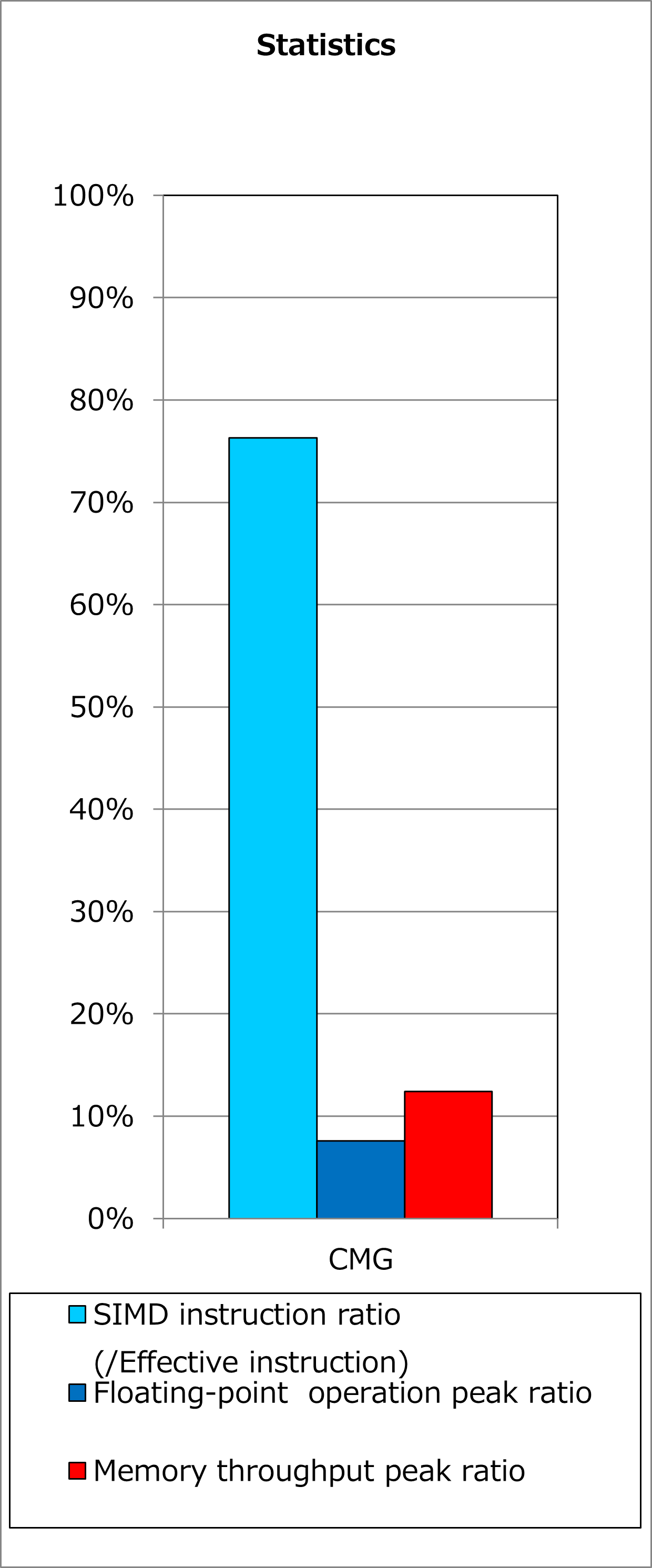
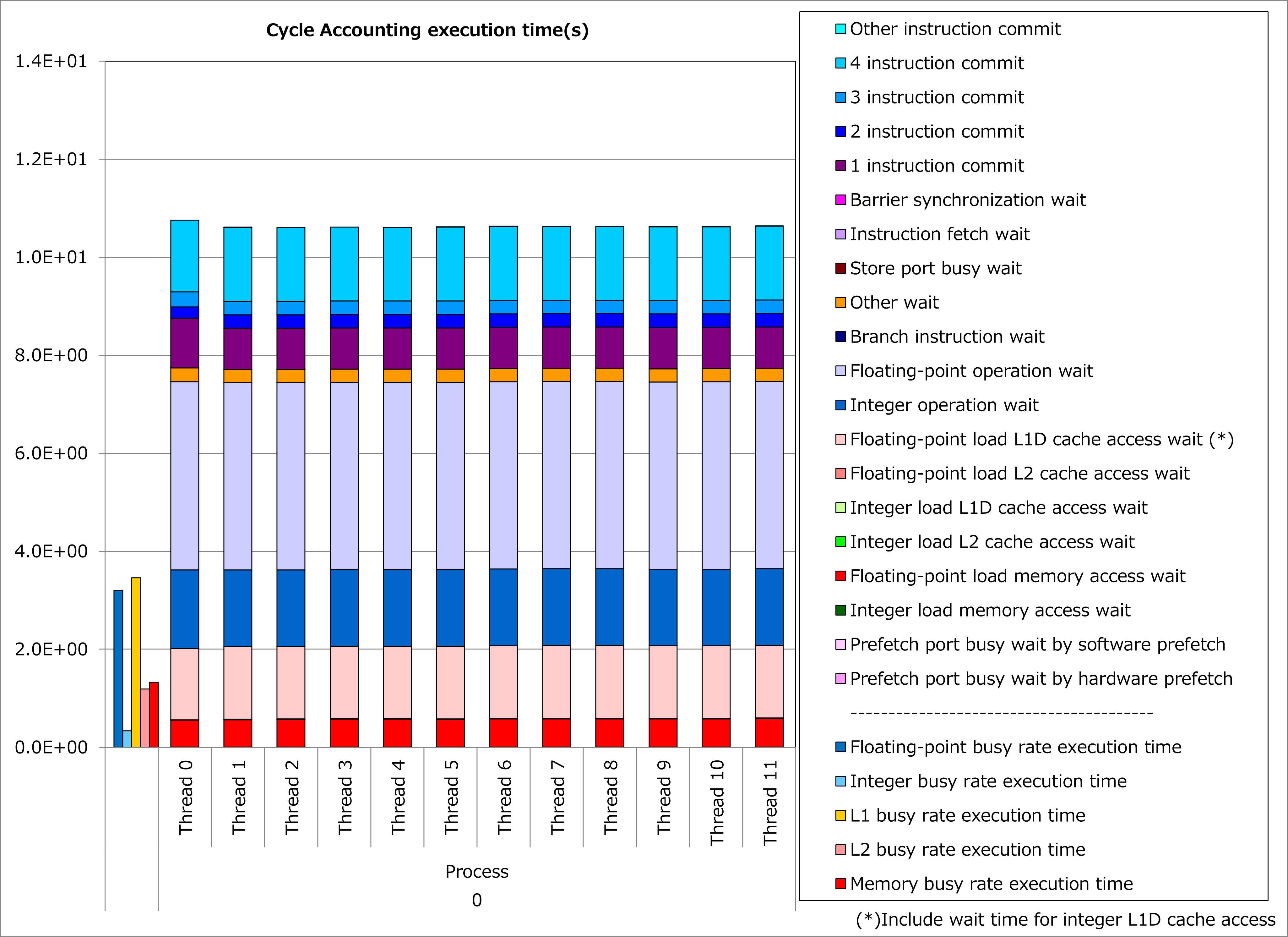
Ratios of SIMD instructions and results of cycle accounting for executions before/after applying the technique are shown in graphs below. A parameter for the loop execution is as follows:
p_Nq = 8
Comparing the lower graph for the technique applied to the upper graph for the original, ratio of SIMD instructions was improved from 53% to 76% and execution time was reduced by 16%.
2.3.3. Real Cases¶
A real case related to this technique is presented in “Meetings for application code tuning on A64FX computer systems” as follows: