2.2. Interchange of Innermost Loop with Small Iteration Count¶
2.2.1. Motivation¶
Using predicate registers on A64FX processors, Fujitsu Fortran/C/C++ compilers can vectorizes loops with any iteration counts. However, if an iteration count of a loop is small and not multiples of SIMD length, the number of calculations inactivated by predicate registers becomes unignorable ratio.
When the iteration count for the innermost loop is small but one for an outer loop is relatively large, interchange of these loops might reduce the ratio of calculations inactivated by predicate registers.
As a result, reduction of inactivated calculations might reduce execution time.
2.2.2. Applied Example¶
Referring to an example presented in “Meetings for application code tuning on A64FX computer systems”, performance improvement by applying this technique is shown below. In this example, a loop for do-variable ich, which has a small iteration count, is interchanged with a loop for do-variable k.
do k = 1, rd_kmax
ip = indexP(k)
length = gas(k,i,j,igasabs(igas,iw)) * PPM * dz_std(k)
do ich = 1, chmax
A1 = AKD(ich,ip-1,1,gasno,iw) * ( 1.0_RP - factP(k) )&
+ AKD(ich,ip ,1,gasno,iw) * ( factP(k) )
A2 = AKD(ich,ip-1,2,gasno,iw) * ( 1.0_RP - factP(k) )&
+ AKD(ich,ip ,2,gasno,iw) * ( factP(k) )
A3 = AKD(ich,ip-1,3,gasno,iw) * ( 1.0_RP - factP(k) )&
+ AKD(ich,ip ,3,gasno,iw) * ( factP(k) )
factPT = factT32(k)*(A3-A2) + A2 + factT21(k)*(A2-A1)
tauGAS(k,ich) = tauGAS(k,ich) + 10.0_RP**factPT * length
enddo
enddo
do ich = 1, chmax
do k = 1, rd_kmax
ip = indexP(k)
A1 = AKD(ip-1,ich,1,gasno,iw) * ( 1.0_RP - factP(k) )&
+ AKD(ip ,ich,1,gasno,iw) * ( factP(k) )
A2 = AKD(ip-1,ich,2,gasno,iw) * ( 1.0_RP - factP(k) )&
+ AKD(ip ,ich,2,gasno,iw) * ( factP(k) )
A3 = AKD(ip-1,ich,3,gasno,iw) * ( 1.0_RP - factP(k) )&
+ AKD(ip ,ich,3,gasno,iw) * ( factP(k) )
factPT = factT32(k)*(A3-A2) + A2 + factT21(k)*(A2-A1)
length = gas(k,i,j,igasabs(igas,iw)) * PPM * dz_std(k)
tauGAS(k,ich) = tauGAS(k,ich) + 10.0_RP**factPT * length
enddo
enddo
Ratios of SIMD instructions and results of cycle accounting for executions before/after applying the technique are shown in graphs below. Parameters for the loop execution are as follows:
rd_kmax = 54, chmax = 5
Comparing the lower graph for the technique applied to the upper graph for the original, execution time was reduced by 51%. At the time, the number of executed instructions for floating-point calculations was reduced by 35% and ratio of active elements in floating-point calculation pipelines was improved from 68% to 86%.
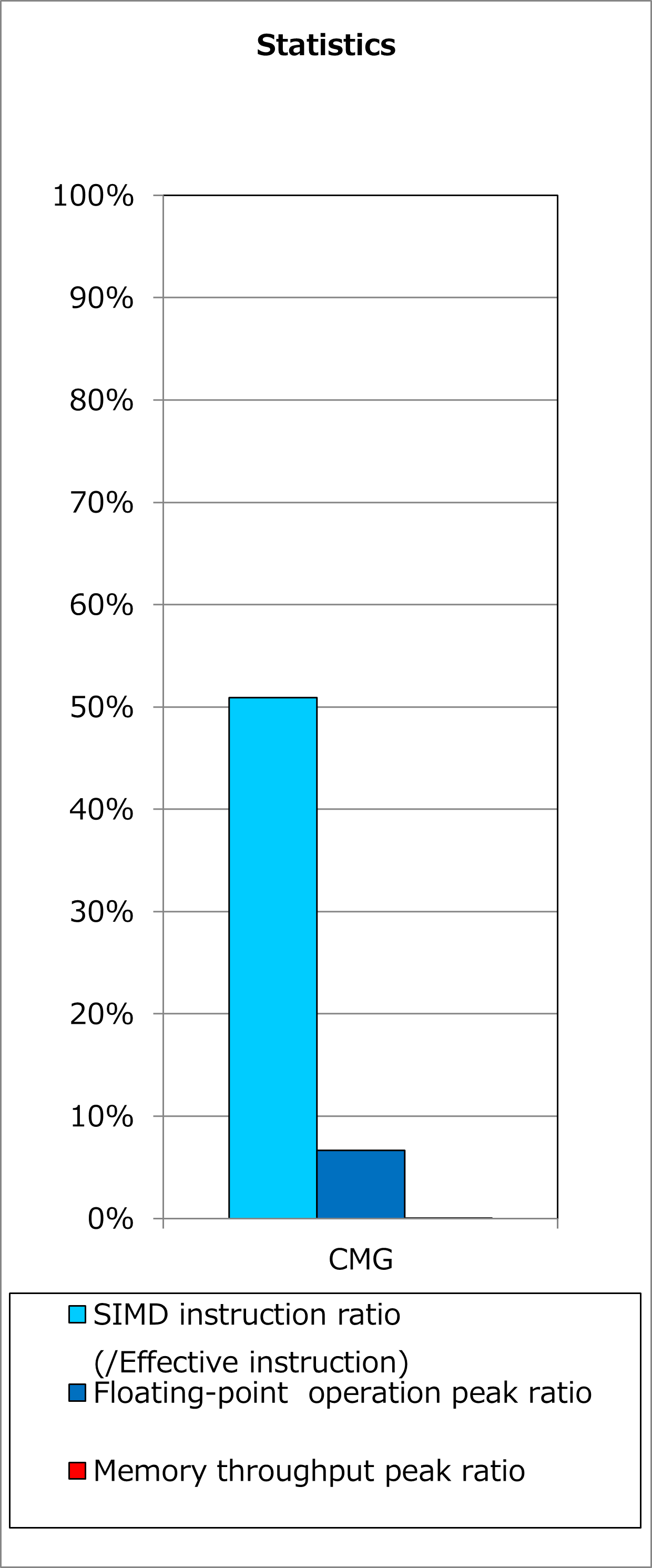
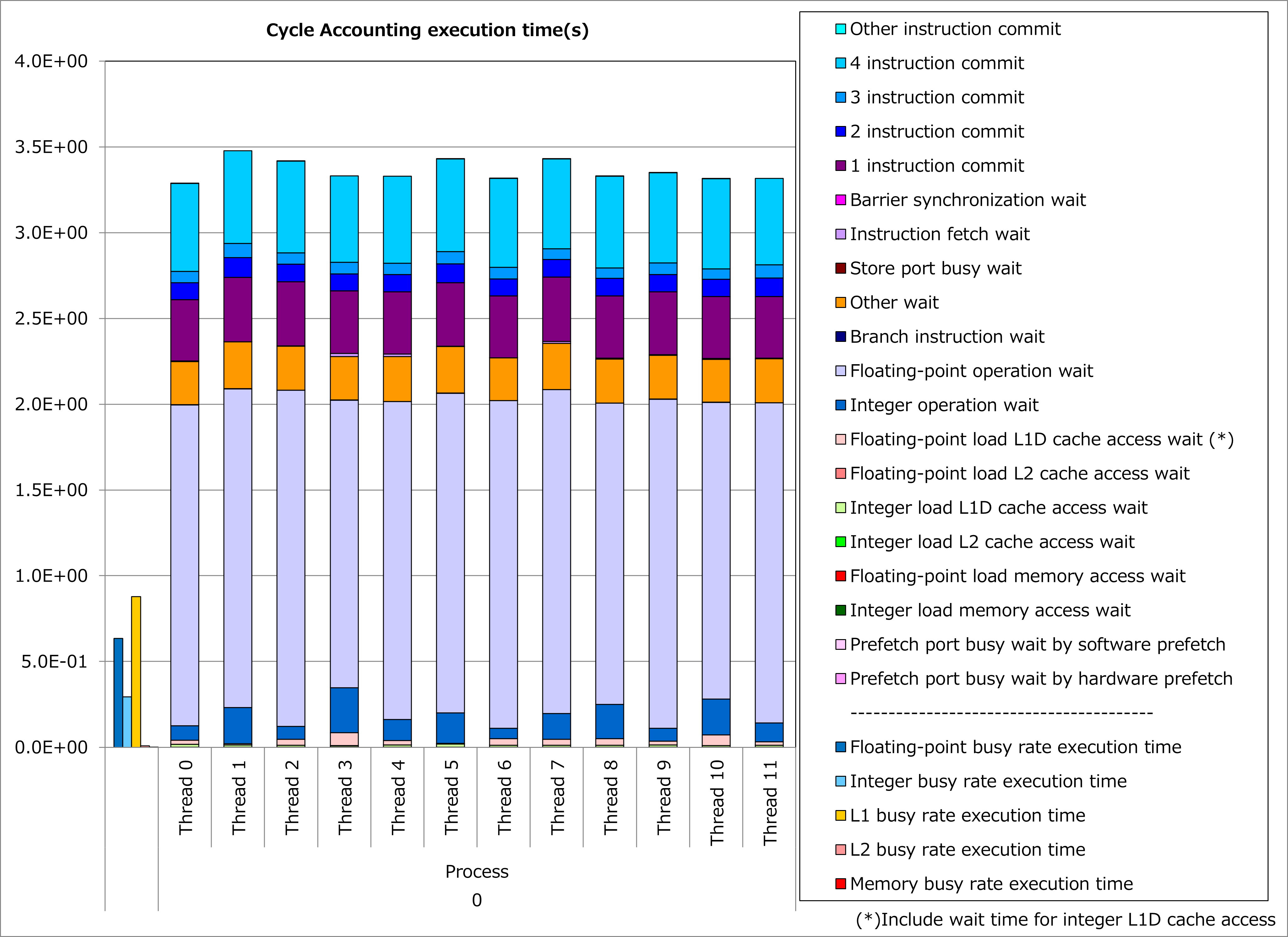
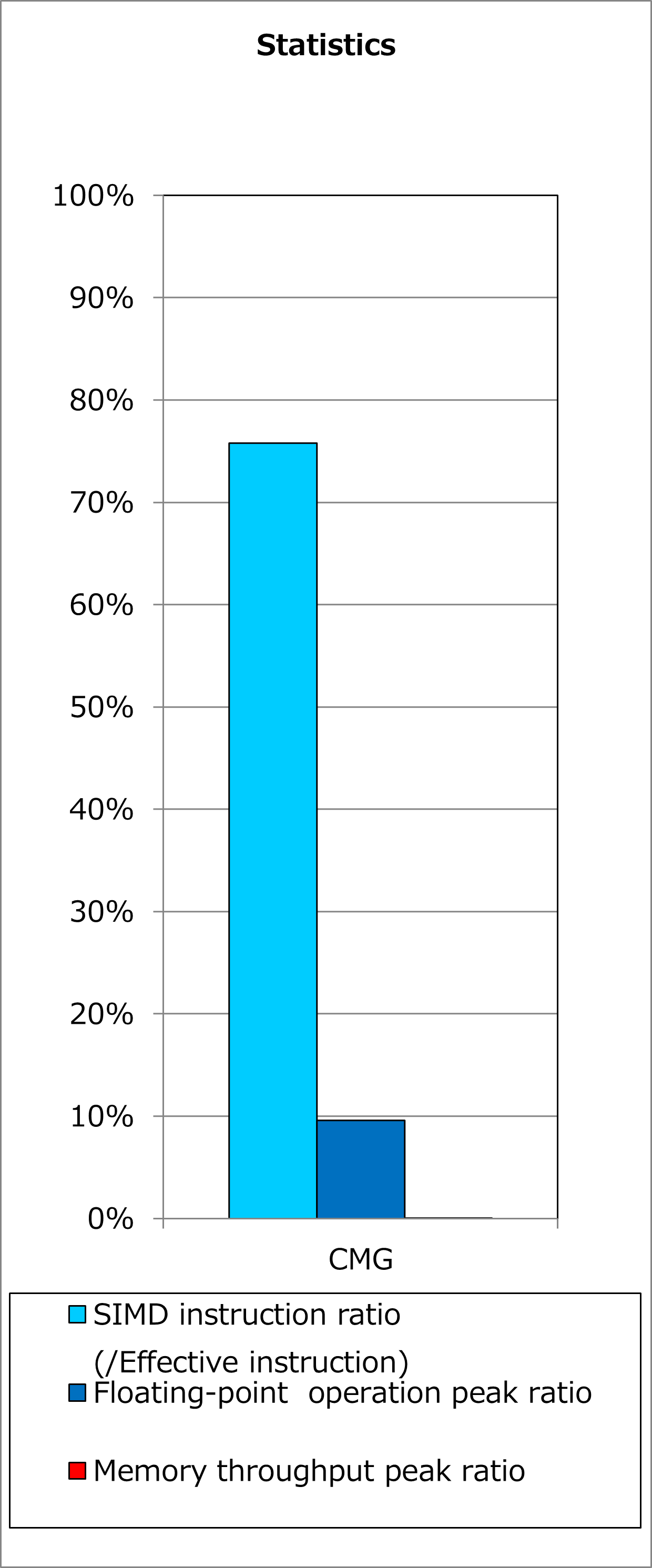
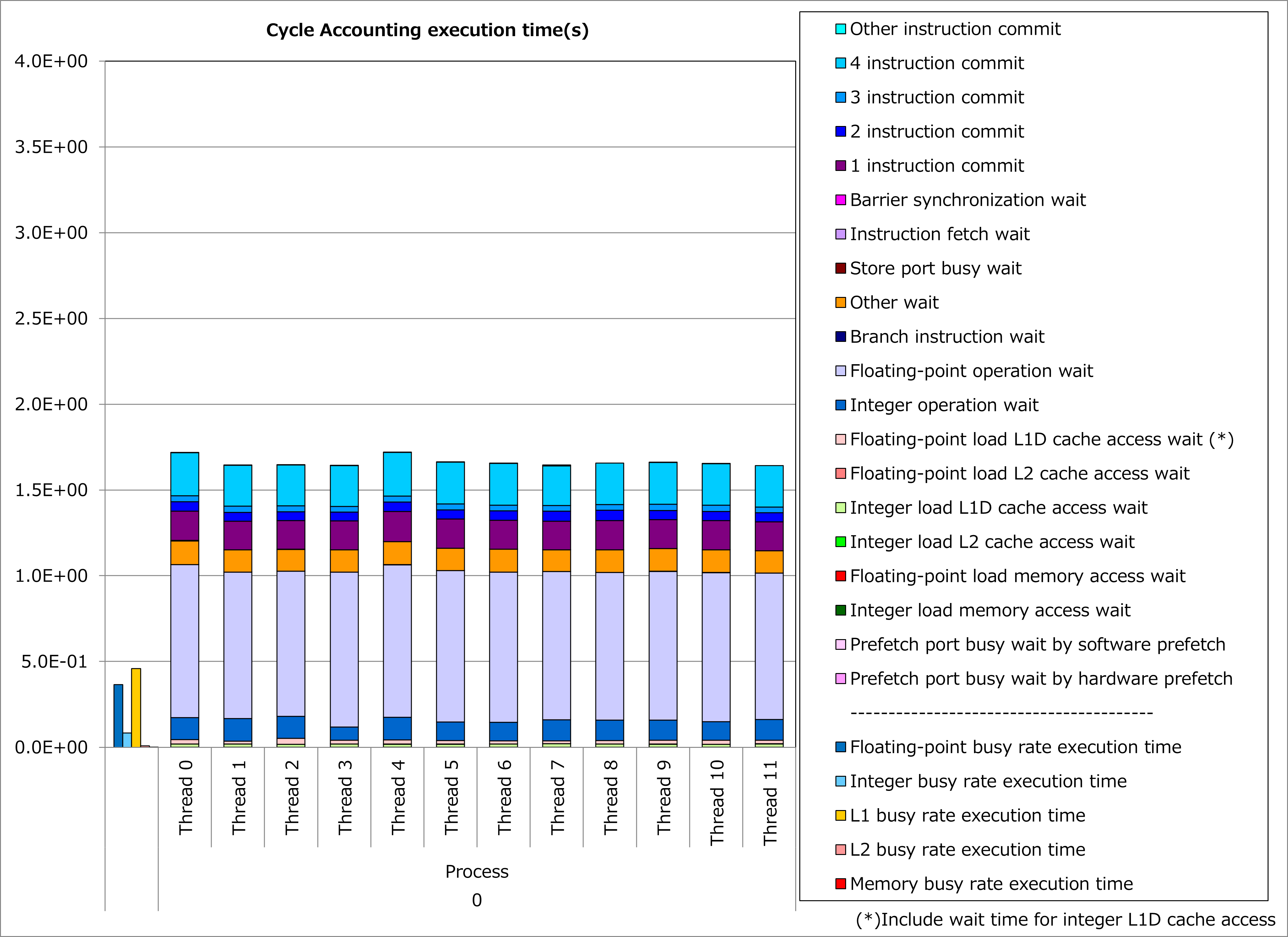
2.2.3. Real Cases¶
A real case related to this technique is presented in “Meetings for application code tuning on A64FX computer systems” as follows: