3. チューニングの作業内容と結果¶
本章では、2.2節( チューニング手順 )の手順にそって実施したチューニングの内容と結果について紹介します。
3.1. 実行時間の計測¶
チューニング実施前に本アプリケーションの実行時間を計測しました。 チューニング効果の検証などで用いるために、本アプリケーションに組み込まれていた時刻の出力ログを利用して、実行時間をいくつかの計測区間に分けました。本文書では本アプリケーションの実行時間を表示する際は、アプリケーション全体の実行時間に加えて、各計測区間の実行時間も表示します。
主な計測区間は、「ソルバー」・「制限関数処理」・「その他」の3つです。そのうち「その他」は、アプリケーション全体の実行時間から、それ以外の2つの実行時間を差し引いたものです。
さらに「ソルバー」は、処理内容の違いから「システム方程式マトリクス計算」・「システム方程式マトリクス構築」・「システム方程式以外の方程式処理」・「ソルバーのその他」に分かれます。そのうち「ソルバーのその他」は「ソルバー」の実行時間から、それ以外の3つの実行時間を差し引いたものです。
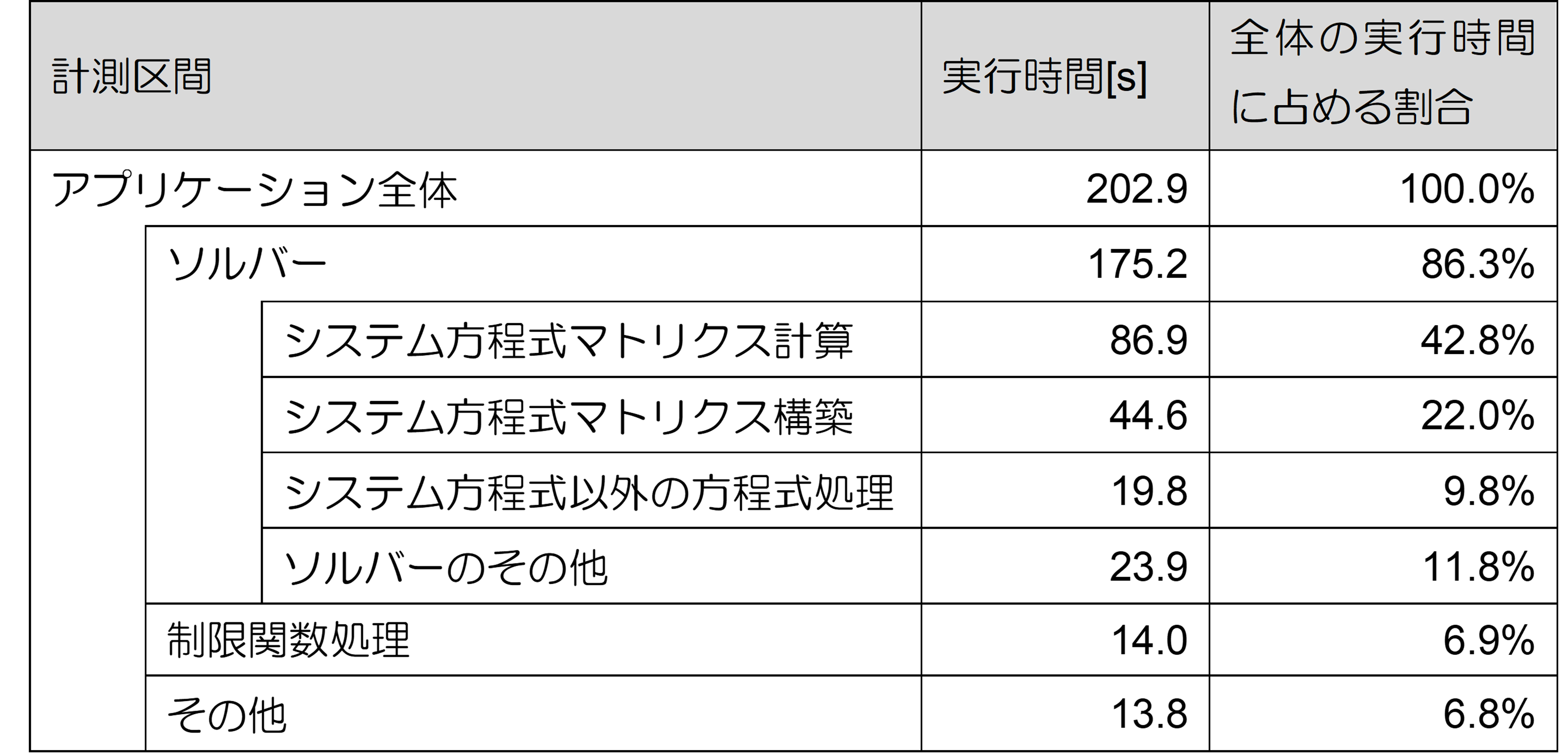
計測したアプリケーション全体の実行時間と、計測区間ごとの実行時間は下表の通りです。下表によると最も実行時間が長い計測区間は「システム方程式マトリクス計算」で、全体の約43%を占めています。
3.2. 関数単位のコストの計測¶
チューニング実施前に富士通製プロファイラ(基本プロファイラ)を利用して関数単位のコストをサンプリング解析にて、計測しました。基本プロファイラの計測結果には1645個の関数とそのコストが出力されました。関数単位のコストはその実行時間に比例し、チューニング対象を選択する際の参考になります。
下表は基本プロファイラの計測結果のうち、コストの高い順に上位10個の関数を抜粋したものです。「計測区間名」のカラムは当該関数がどの計測区間に含まれているかを示しています。「コスト」のカラムは基本プロファイラが出力した関数単位のコストです。「コストの割合」のカラムは、アプリケーション全体のコストに対する各関数単位のコストの割合を示し、「コストの割合の累積」のカラムは、各関数単位のコストの割合をコストの高い順に1番目の関数から当該関数まで足し合わせた結果です。
関数名 |
計測区間名 |
コスト |
コストの割合[%] |
コストの割合の累積[%] |
|
|---|---|---|---|---|---|
0 |
(アプリケーション全体) |
― |
10145395 |
100.00 |
― |
1 |
calc_function_1 |
システム方程式マトリクス計算 |
2359630 |
23.26 |
23.26 |
2 |
function_of_MPI_1 |
(プロセス間通信) |
1818309 |
17.92 |
41.18 |
3 |
function_of_MPI_2 |
(プロセス間通信) |
1090237 |
10.75 |
51.93 |
4 |
make_function_1 |
システム方程式マトリクス構築 |
359086 |
3.54 |
55.47 |
5 |
make_function_2 |
システム方程式マトリクス構築 |
323755 |
3.19 |
58.66 |
6 |
limiter_function_1 |
制限関数処理 |
290204 |
2.86 |
61.52 |
7 |
calc_function_2 |
システム方程式マトリクス計算 |
187961 |
1.85 |
63.37 |
8 |
make_function_3 |
システム方程式マトリクス構築 |
176418 |
1.74 |
65.11 |
9 |
calc_function_3 |
システム方程式マトリクス計算 |
165032 |
1.63 |
66.74 |
10 |
make_function_4 |
システム方程式マトリクス構築 |
156562 |
1.54 |
68.28 |
上位3個の関数のコストはすべて10%を超え、3つ合わせてアプリケーション全体のコストの50%以上を占めています。最もコストが高い関数は「システム方程式マトリクス計算」の計測区間に含まれる calc_function_1 関数で、全体の約23%を占めています。次にコストが高いのは function_of_MPI_1 関数と function_of_MPI_2 関数ですが、プロセス間通信の関数でありチューニング対象にはなりません。
一方、4位以下の関数のコストをみると、4位の時点で全体の3.54%、10位の時点で1.54%まで低下しており、コストが多くの関数に分散していることがわかります。
3.3. チューニングの実施¶
前述の手順と計測結果に基づいて、チューニングを実施しました。本節ではその内容と結果を紹介します。
3.3.1. チューニング項目の一覧¶
下表は、本アプリケーションに対して実施した全てのチューニング項目の内容と対象関数を示したものです。各チューニング項目は実施した順に並んでおり、その内容としてチューニングの概要・方法・狙いと、対象関数、および対象関数が含まれる計測区間を示しています。4章( チューニング項目 )ではこの中から10個のチューニング項目を抜粋して詳しく説明します。
下表の「チューニングの方法」のカラムでは、最適化制御行の追加や、翻訳時オプションの変更など、チューニングの実施手法を簡単に記載しています。また、「チューニングの狙い」のカラムでは、チューニングを実施する際に意図した改善点などを記載しています。この「チューニングの狙い」のカラムは、「富岳」の利用者ポータルに掲載されている『プログラミングガイド チューニング編』の目次の大項目を参考にしたものです。
項番 |
チューニングの概要 |
チューニングの方法 |
チューニングの狙い |
対象関数 |
対象関数が含まれる処理区間名 |
本文書での記載箇所 |
|---|---|---|---|---|---|---|
1 |
小回転ループの一重化およびループ展開 |
ソースコード変更 |
命令数の削減 |
calc_function_1 |
システム方程式マトリクス計算 |
― |
2 |
プリフェッチ命令の発行 |
最適化制御行の追加のみ |
レイテンシの隠蔽によるデータアクセス待ち改善 |
calc_function_1 |
システム方程式マトリクス計算 |
― |
3 |
ループ内の配列足し込みの連続アクセス化 |
ソースコード変更 |
レイテンシの隠蔽によるデータアクセス待ち改善 |
calc_function_1 |
システム方程式マトリクス計算 |
― |
4 |
ループ展開 |
ソースコード変更 |
命令数の削減、ループ最適化による命令スケジューリングの改善 |
calc_function_1 |
システム方程式マトリクス計算 |
― |
5 |
ループ展開 |
ソースコード変更 |
命令数の削減、ループ最適化による命令スケジューリングの改善 |
calc_function_1 |
システム方程式マトリクス計算 |
― |
6 |
faddv命令の抑止 |
翻訳時オプション変更 |
命令数の削減 |
calc_function_1 |
システム方程式マトリクス計算 |
― |
7 |
ループ展開 |
最適化制御行の追加のみ |
命令数の削減、ループ最適化による命令スケジューリングの改善 |
make_function_2 |
システム方程式マトリクス構築 |
― |
make_function_3 |
システム方程式マトリクス構築 |
|||||
8 |
マトリクスの非対角項を並び替え |
ソースコード変更 |
連続アクセス化 |
calc_function_1 |
システム方程式マトリクス計算 |
― |
9 |
小回転ループのSIMD化抑止 |
最適化制御行の追加のみ |
命令数の削減 |
calc_function_3 |
システム方程式マトリクス計算 |
― |
make_function_1 |
システム方程式マトリクス構築 |
|||||
make_function_4 |
システム方程式マトリクス構築 |
|||||
make_function_5 |
システム方程式マトリクス構築 |
|||||
make_function_6 |
システム方程式マトリクス構築 |
|||||
10 |
除算処理のSIMD化と小回転ループのSIMD化抑止 |
ソースコード変更 |
SIMD化の促進による演算待ち改善 |
calc_function_3 |
システム方程式マトリクス計算 |
4.1節 |
11 |
ループ展開によるload/store削減 |
ソースコード変更 |
命令数の削減、ループ最適化による命令スケジューリングの改善 |
calc_function_1 |
システム方程式マトリクス計算 |
4.2節 |
12 |
ループアンスイッチング |
最適化制御行の追加のみ |
レイテンシの隠蔽によるデータアクセス待ち改善 |
make_function_5 |
システム方程式マトリクス構築 |
― |
13 |
ループ展開 |
最適化制御行の追加のみ |
命令数の削減、ループ最適化による命令スケジューリングの改善 |
make_function_2 |
システム方程式マトリクス構築 |
― |
14 |
領域分割のパラメータ変更 |
実行時の設定変更 |
MPI並列計算のプロセス間負荷バランスを向上 |
― |
― |
― |
15 |
余分な型変換の削減 |
ソースコード変更 |
命令数の削減 |
make_function_2 |
システム方程式マトリクス構築 |
― |
16 |
ループ一重化によるSIMD化促進 |
ソースコード変更 |
SIMD化の促進による演算待ち改善 |
make_function_6 |
システム方程式マトリクス構築 |
4.3節 |
17 |
ループ分割によるSIMD化促進 |
ソースコード変更 |
SIMD化の促進による演算待ち改善 |
make_function_2 |
システム方程式マトリクス構築 |
― |
18 |
インライン展開 |
ソースコード変更 |
命令数の削減 |
limiter_function_1 |
制限関数処理 |
― |
make_function_1 |
システム方程式マトリクス構築 |
|||||
make_function_4 |
システム方程式マトリクス構築 |
|||||
make_function_9 |
システム方程式マトリクス構築 |
|||||
calc_function_2 |
システム方程式マトリクス計算 |
|||||
calc_function_3 |
システム方程式マトリクス計算 |
|||||
calc_function_5 |
システム方程式マトリクス計算 |
|||||
19 |
ループ回転方向変更 |
ソースコード変更 |
レイテンシの隠蔽によるデータアクセス待ち改善 |
othSolv_function_3 |
システム方程式以外の方程式処理 |
4.4節 |
20 |
不変式の移動 |
ソースコード変更 |
レイテンシの隠蔽による演算待ち改善 |
make_function_8 |
システム方程式マトリクス構築 |
― |
21 |
ループ分割 |
ソースコード変更 |
命令数の削減、ループ最適化による命令スケジューリングの改善 |
make_function_8 |
システム方程式マトリクス構築 |
― |
22 |
ループ内配列のレジスタ化 |
ソースコード変更 |
レイテンシの隠蔽によるデータアクセス待ち改善 |
make_function_8 |
システム方程式マトリクス構築 |
― |
23 |
計算式のコスト削減 |
ソースコード変更 |
命令数の削減 |
make_function_8 |
システム方程式マトリクス構築 |
― |
24 |
SVE ACLEによるSIMD化 |
ソースコード変更 |
SIMD化の促進による演算待ち改善 |
calc_function_4 |
システム方程式マトリクス計算 |
4.5節 |
25 |
ビルトインプリフェッチ |
ソースコード変更 |
レイテンシの隠蔽によるデータアクセス待ち改善 |
make_function_2 |
システム方程式マトリクス構築 |
4.6節 |
make_function_3 |
システム方程式マトリクス構築 |
|||||
make_function_7 |
システム方程式マトリクス構築 |
|||||
26 |
SIMD化促進のための配列静的確保 |
ソースコード変更 |
SIMD化の促進による演算待ち改善 |
calc_function_1 |
システム方程式マトリクス計算 |
― |
27 |
クローンチューニングおよびループ展開 |
ソースコード変更 |
レイテンシの隠蔽によるデータアクセス待ち改善 |
make_function_6 |
システム方程式マトリクス構築 |
― |
make_function_12 |
システム方程式マトリクス構築 |
|||||
28 |
除算処理をループの外側に移動しSIMD化 |
ソースコード変更 |
SIMD化の促進による演算待ち改善 |
make_function_7 |
システム方程式マトリクス構築 |
4.7節 |
29 |
ビルトインプリフェッチ |
ソースコード変更 |
レイテンシの隠蔽によるデータアクセス待ち改善 |
othSolv_function_1 |
システム方程式以外の方程式処理 |
― |
othSolv_function_2 |
システム方程式以外の方程式処理 |
|||||
othSolv_function_5 |
システム方程式以外の方程式処理 |
|||||
30 |
インライン展開によるSIMD化促進 |
ソースコード変更 |
SIMD化の促進による演算待ち改善 |
function_1 |
システム方程式以外の方程式処理 |
― |
function_2 |
システム方程式以外の方程式処理 |
|||||
31 |
スレッド並列化 |
ソースコード変更 |
スレッド並列チューニング |
calc_function_1 |
システム方程式マトリクス計算 |
― |
make_function_7 |
システム方程式マトリクス構築 |
|||||
32 |
load命令のスケジューリング改善 |
ソースコード変更 |
ループ最適化による命令スケジューリングの改善 |
othSolv_function_4 |
システム方程式以外の方程式処理 |
― |
33 |
ループ外への不変式の移動 |
ソースコード変更 |
ループ最適化による命令スケジューリングの改善 |
calc_function_2 |
システム方程式マトリクス計算 |
4.8節 |
34 |
最適化制御行を使わないループ展開 |
ソースコード変更 |
命令数の削減、ループ最適化による命令スケジューリングの改善 |
calc_function_4 |
システム方程式マトリクス計算 |
4.9節 |
35 |
ループ内配列のレジスタ化 |
ソースコード変更 |
レイテンシの隠蔽によるデータアクセス待ち改善 |
calc_function_4 |
システム方程式マトリクス計算 |
― |
calc_function_5 |
システム方程式マトリクス計算 |
|||||
36 |
ループインターリーブ |
ソースコード変更 |
レイテンシの隠蔽による演算待ち改善 |
calc_function_1 |
システム方程式マトリクス計算 |
― |
37 |
余分な型変換の削減 |
ソースコード変更 |
命令数の削減 |
calc_function_1 |
システム方程式マトリクス計算 |
― |
38 |
プリフェッチ命令の発行 |
ソースコード変更 |
レイテンシの隠蔽によるデータアクセス待ち改善 |
calc_function_1 |
システム方程式マトリクス計算 |
― |
39 |
ループ一重化 |
ソースコード変更 |
ループ最適化による命令スケジューリングの改善 |
make_function_6 |
システム方程式マトリクス構築 |
― |
make_function_5 |
システム方程式マトリクス構築 |
|||||
40 |
クローンチューニングおよびインライン展開 |
ソースコード変更 |
命令数の削減、ループ最適化による命令スケジューリングの改善 |
make_function_6 |
システム方程式マトリクス構築 |
― |
make_function_5 |
システム方程式マトリクス構築 |
|||||
make_function_7 |
システム方程式マトリクス構築 |
|||||
41 |
2次元配列のメモリ配置改善 |
ソースコード変更 |
連続アクセス化 |
allocate_array |
(アプリケーション全体) |
4.10節 |
clear_array |
(アプリケーション全体) |
|||||
deallocate_array |
(アプリケーション全体) |
|||||
reallocate_array |
(アプリケーション全体) |
|||||
allocate_array_2 |
(アプリケーション全体) |
|||||
deallocate_array_2 |
(アプリケーション全体) |
|||||
reallocate_array_2 |
(アプリケーション全体) |
|||||
42 |
項番41の改善をベースとしたSIMD化の改善 |
ソースコード変更 |
SIMD化の促進による演算待ち改善 |
calc_function_1 |
システム方程式マトリクス計算 |
― |
43 |
クローンチューニング |
ソースコード変更 |
ループ最適化による命令スケジューリングの改善 |
make_function_7 |
システム方程式マトリクス構築 |
― |
44 |
ビルトインプリフェッチ箇所のSIMD化抑止 |
最適化制御行の追加のみ |
命令数の削減 |
make_function_7 |
システム方程式マトリクス構築 |
― |
上表の44個のチューニング項目のうち、本文書では、以下のような特徴を持つ10個のチューニング項目を4章( チューニング項目 )で紹介します。
局所的なコード変更によるチューニング
最適化制御行で対応できる項目(4.2節で紹介)などの、ソースコードの変更を最小限に抑えて性能を改善するチューニング項目です。
4.2節:ループ展開によるload/store削減
4.3節:ループ一重化によるSIMD化促進
4.4節:ループ回転方向変更
4.7節:除算処理をループの外側に移動しSIMD化
4.8節:ループ外への不変式の移動
4.9節:最適化制御行を使わないループ展開
A64FX プロセッサの性能をより引き出す高度なチューニング
Arm 独自の機能である SVE ACLE を利用するチューニング(4.5節で紹介)などの、A64FX プロセッサの特徴を活かして性能をより引き出すためのチューニング項目です。
4.5節:SVE ACLEによるSIMD化
4.6節:ビルトインプリフェッチ
多くの関数で利用される関数へのチューニング
4.10節は2次元配列のメモリ確保・開放を行う関数を対象としたチューニング項目です。関数自体のコストは低いですが、配列のメモリ確保・開放は、本アプリケーションの様々な箇所で利用されるため、アプリケーション全体の性能に影響を与えます。
4.10節:2次元配列のメモリ配置改善
3.3.2. アプリケーションの改善結果¶
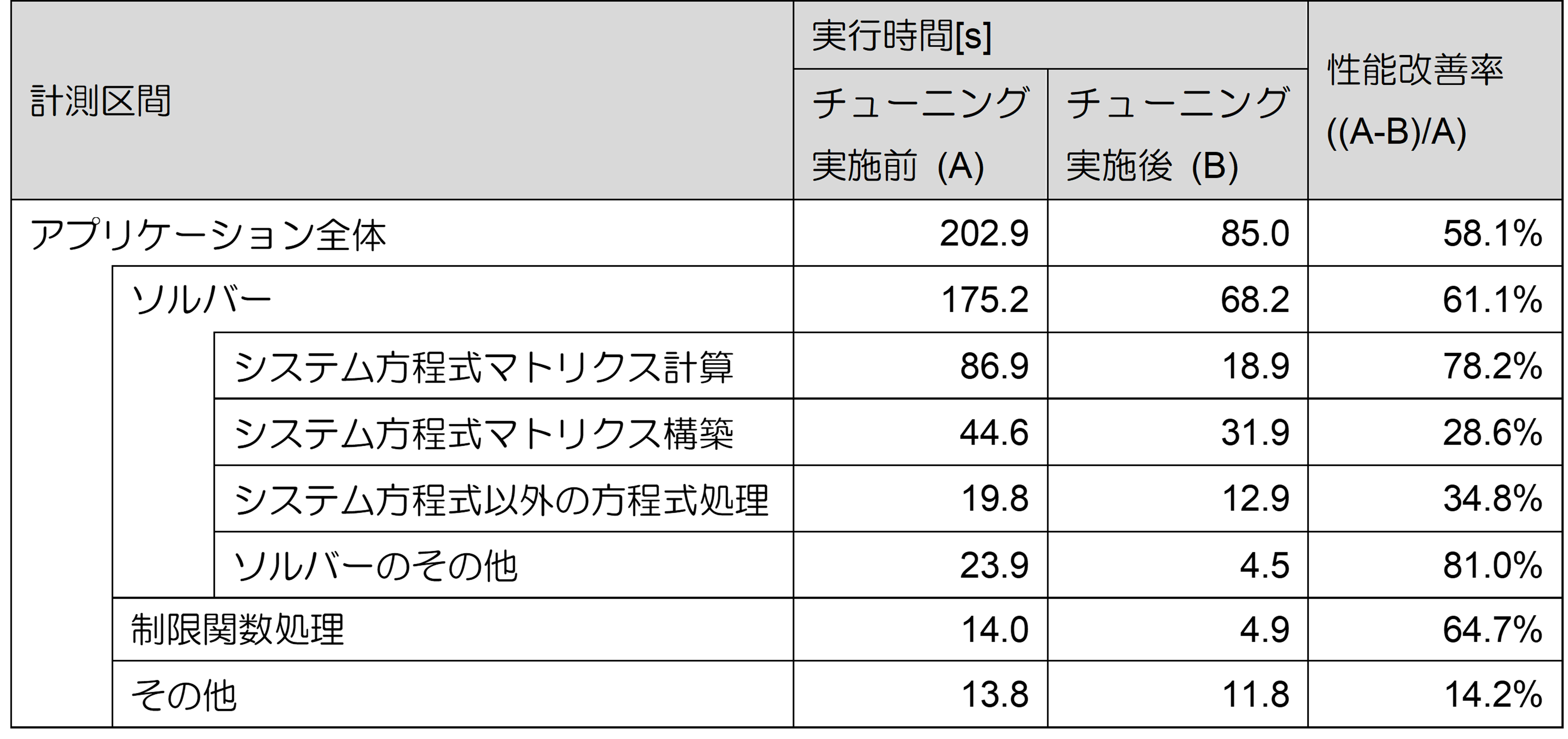
以下は、チューニングを実施する前と、前述の全てのチューニング項目(項番1から44まで)を実施した後の、実行時間および性能改善率です。チューニング実施後のアプリケーション全体の性能改善率は58%に達し、実行時間はチューニング実施前の半分以下になり、目標を達成しました。
本アプリケーションへのチューニングでは、3.3.1項( チューニング項目の一覧 )の44個のチューニング項目を上から順に実施する過程で、アプリケーションの性能を複数回計測しました。以下のグラフは、アプリケーション全体および各計測区間について、実行時間と、チューニング実施前に対する性能改善率が、チューニング項目によってどのように推移したかを示しています。なお、以下のグラフの実行時間は各計測区間の積み上げグラフで、縦棒の高さと上部の数字はアプリケーション全体の実行時間を示します。
両グラフの横軸は、ともに3.3.1項( チューニング項目の一覧 )のチューニング項目の項番1から該当番号までの項番を実施した後に計測した結果を表します。たとえば、横軸8の位置にあるデータは、チューニング項目の項番8まで(項番1から8)を実施した後の計測結果です。ただし、横軸0の位置にあるデータは、チューニング実施前のデータです。
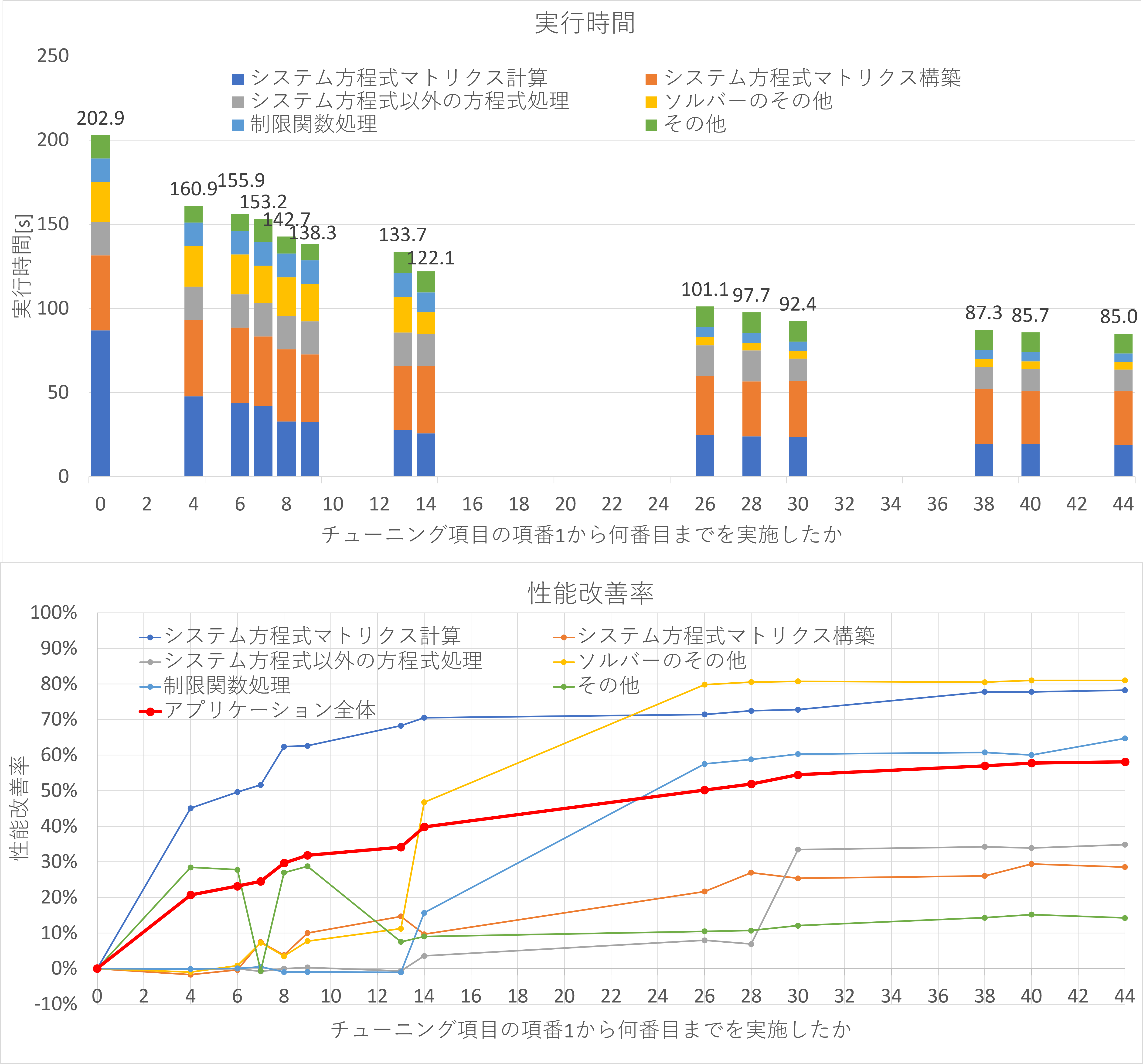
上記グラフによると、チューニング項目の項番1から13までで、アプリケーション全体の性能は約34%改善し、「システム方程式マトリクス計算」の性能は約68%改善しました。ここでは、基本プロファイラのコストが高い順に関数を選択・分析し、項番13までのチューニング項目では上位8個までの関数にチューニングを実施しました。実施した13個のチューニング項目のうち7個は、最もコストが高い calc_function_1 関数を対象としたチューニングです。
項番14では、アプリケーション全体の性能が約6%改善しました。項番14は、領域分割のパラメータ変更によるプロセス間の負荷バランスの向上です。これはアプリケーションを開発した ISV の知見に基づき、問題点および改善策を洗い出した結果です。
項番15から44までで、アプリケーション全体の性能がさらに約18%向上しました。ここでは、主に低コスト関数をチューニングの対象としたため、チューニング1項目あたりのアプリケーション全体への性能改善率が項番14までと比べて小さくなりました。
また、計測区間ごとの性能改善率をみると、項番1から13は「システム方程式マトリクス計算」、項番14は「ソルバーのその他」、項番15から26は主に「制限関数処理」、項番28から30は「システム方程式以外の方程式処理」に、大きく寄与しています。
最終的には、アプリケーション全体の約52%を占める上位30個までの関数(チューニング対象外のプロセス間通信の関数を除く)を選択・分析し実施した40個のチューニング項目、プロセス間の負荷バランス向上のチューニング項目、スレッド並列化のチューニング項目、コストは低いが多くの関数で利用される関数への2個のチューニング項目(そのうち1つは 4.10節( 2次元配列のメモリ配置改善 )で紹介)、の合計44個のチューニング項目を実施しました。結果として、アプリケーション全体の実行時間が、202.9秒から85.0秒に短縮(約2.4倍の高速化)し、当初の目標(2倍以上の高速化)を達成しました
「富岳」での大規模シミュレーションを実現するために
チューニング項目のうち項番14と項番31は、利用者が求める大規模なシミュレーションを行う際に、数十万並列の計算リソースを活用するために特に重要となる項目です。
項番14:領域分割のパラメータ変更項番14では、MPI 並列計算のプロセス間負荷バランスを向上させるために、本アプリケーション内で設定されている領域分割のパラメータを変更しました。負荷バランスが悪いとプロセス間の通信待ち時間が長くなり、並列数が増えるほどその影響が大きくなります。そのため、プロセス間で計算量をできるだけ均等に分配することは重要なポイントです。
項番31:スレッド並列化本アプリケーションは、当初スレッド並列に対応していませんでした。しかし、利用者が求めるような数十万並列のシミュレーションを、計算リソースをなるべく効率的に活用して行うためには、スレッド並列は重要な項目になります。そこでチューニングの1つとして、初めてスレッド並列化を行いました。まず今回のチューニングでは、データ競合などの阻害要因がなく比較的に取り組みやすい、calc_function_1 関数と make_function_7 関数(チューニング実施前の関数コストの割合は、2つ合わせて全体の約25%)に限定して、スレッド並列化を行いました。
数十万並列の大規模な計算に比べると、今回のチューニングの性能評価で行った計算は小規模でした。そのため、上記2項目を含む全てのチューニング項目を実施したのち、約8億要素を持つ大規模モデルを用いて、「富岳」で動作検証を行いました。「富岳」の4000ノード超の計算リソースを使い、MPI 並列とスレッド並列(スレッド数4)を組み合わせたハイブリッド並列によって、約22万並列までの動作を確認し、さらに約20万並列までの速度向上が確認できました。これは、上記2項目を含む今回のチューニングによる成果で、今後スレッド並列化の対象範囲拡大などさらなる改善を行うことで、より大規模なシミュレーションも実現できると考えています。